W 2016 roku ukazał się raport Fundacji Batorego z badania kart do głosowania z wyborów do sejmików województw 2014, w związku z wątpliwościami dotyczącymi uczciwości tych wyborów. Powodem tych wątpliwości były opóźnienia w podaniu wyników, awaria systemu informatycznego oraz duża liczba głosów nieważnych.

W stu losowych komisjach przeliczono głosy jeszcze raz. Dzięki temu, że była to próba losowa, wnioski mogły być uogólnione na wszystkie komisje. Jednym z nich była powszechność niewielkich błędów, głównie wynikających z niepoprawnej klasyfikacji głosów nieważnych. Takie błędy wystąpiły w ponad połowie (!) komisji, natomiast w sumie dotyczyły jednego procenta głosów. Były też symetryczne, to znaczy niepowiązane z żadną z partii – czyli najprawdopodobniej przypadkowe.
W drugiej turze wyborów prezydenckich z 2025 roku na jaw wyszły znacznie większe błędy, rzędu kilkuset głosów. Czy były powszechne? Czy któryś z kandydatów na tym zyskał? A może to nie były przypadkowe błędy, tylko celowe działanie?
W niniejszym artykule odpowiadam na te i inne pytania. Podzieliłem go na dwie części. W pierwszej przedstawiam historię z wyborami: jak to się stało, że w którymś momencie połowa Polaków chciała ponownego przeliczenia głosów. W drugiej części w możliwie przystępny sposób tłumaczę, jak przy pomocy statystyki można wykryć komisje, w których podano złe wyniki.
Exit poll, late poll
Za początek tej historii można przyjąć podanie wyników late poll, które różniły się jakościowo od exit poll (dzień wyborów, 1 czerwca 2025).
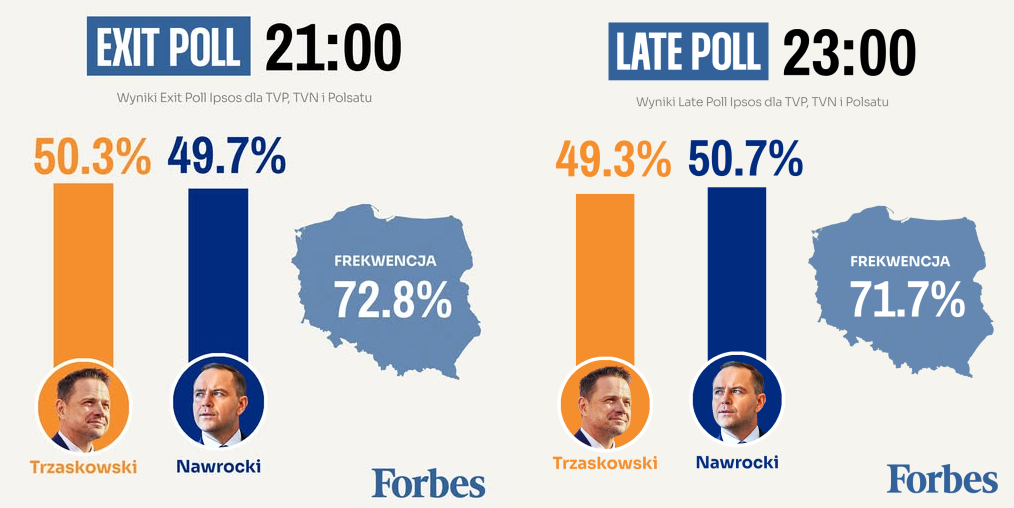
Przypomnijmy, że exit poll to badanie ankietowe na wyborcach zaraz po zagłosowaniu. Losowo wybrane osoby mają wskazać, na kogo przed chwilą zagłosowali. Poza naturalnym błędem losowym wynikającym z tego, że badamy tylko niewielką część wyborców, problemem są tu braki danych. Część wyborców nie chce się przyznać, na kogo zagłosowali, i trzeba to “zgadnąć”. Z kolei late poll bazuje na rzeczywistych wynikach, choć nie wszystkich. Problem z brakami nie występuje, danych jest więcej i wyniki (wciąż szacunkowe) są znacznie bardziej wiarygodne.
Różnica między tymi szacunkami mieściła się w granicach podanego błędu pomiaru (który swoją drogą nie jest łatwo policzyć z racji braków danych), ale ponieważ były one bardzo bliskie 50%, to nastąpiła zmiana jakościowa: przegrany kandydat w exit poll stał się wygranym w late poll. Oliwy do ognia dolał fakt, że to wyniki exit poll, które są szacowane przez niezależny od PKW instytut, były bliższe wcześniejszym sondażom.
Anomalie w komisjach
Niedługo po ogłoszeniu wyników pojawiły się pierwsze analizy pokazujące, że w niektórych komisjach wynik drugiej tury jest nie do pogodzenia z wynikami pierwszej, a na dodatek częściej tracił na tym Trzaskowski (Onet, 5 czerwca).
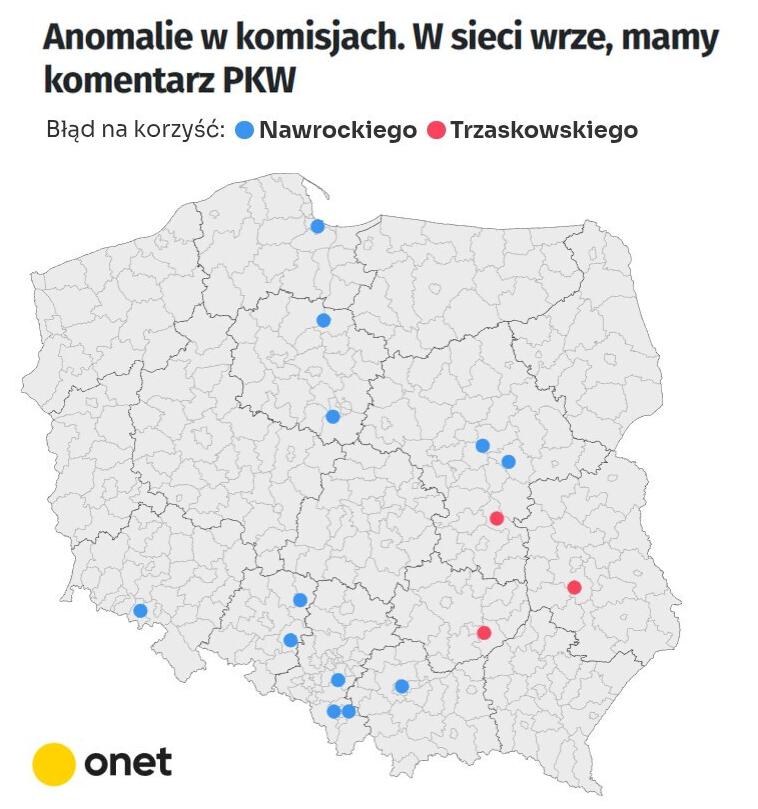
Muszę przyznać, że gdy pierwszy raz o tym usłyszałem, wydawało mi się to raczej niemożliwe. Przypuszczałem, że chodzi tu o tak zwany problem porównań wielokrotnych. Mamy ponad 30 tysięcy komisji, w każdej szukamy dziwnych wyników, więc w którejś musimy je znaleźć. Było inaczej.
Komisja nr 95 w Krakowie
W jednej z komisji w Krakowie Nawrocki otrzymał 218 głosów w pierwszej turze i 1132 w drugiej. Z kolei Trzaskowski 550 w pierwszej i 540 w drugiej. Innymi słowy, w pierwszej turze Trzaskowski uzyskał dwa i pół razy więcej głosów od Nawrockiego, a w drugiej dwa razy mniej.
Oczywiście może tak się zdarzyć: wszyscy, którzy w pierwszej turze nie zagłosowali na Nawrockiego, mogli zrobić to w drugiej. Teoretycznie w drugiej turze mogli też głosować zupełnie inni wyborcy, ale całkowita liczba uprawnionych wynosiła 2000, więc taka możliwość była mocno ograniczona (taka sytuacja może mieć miejsce w komisjach nadmorskich, w których wyborcy mogą się zupełnie zmienić). Z moich dość prostych obliczeń wychodziło, że wszystko by się świetnie zgadzało, gdy wynik w drugiej turze był odwrotny. I jak się okazało, tak właśnie było, komisja w Krakowie przyznała się później, że odwrotnie zapisała głosy.

Taka pomyłka brzmi dość absurdalnie, ale procedura wygląda tak, że po przeliczeniu głosów trzeba ręcznie podać wyniki. Mamy aplikację z dwoma okienkami i cóż, wystarczy źle spojrzeć i podać liczby w złej kolejności. Co prawda wszyscy muszą się pod tym podpisać, ale pamiętajmy, że członkowie komisji najpierw cały dzień wydają karty, a potem tego samego dnia liczą głosy, czasem do późnych godzin nocnych. Nie jest zaskakujące, że w niewielkiej liczbie komisji takie rzeczy mogą się zdarzyć.
Ile było takich komisji?
W tym momencie trzeba było sobie zadać pytanie, jak dużo jest takich przypadków i czy są symetryczne. Oszacowanie ich liczby to trudniejsze zadanie, bo żeby wykryć błędy prostymi metodami, pomyłka musi być odpowiednio spektakularna. Tym zajmiemy się później, natomiast mnie w tamtym czasie interesowała głównie symetria – i nie zauważyłem żadnych odstępstw od niej, wbrew temu, co twierdził Onet.
Protest
Spodziewałem się, że temat przycichnie, ale dopiero zaczął się rozkręcać. Pojawiły się kolejne analizy pokazujące, że z wynikami jest coś nie tak, wraz z nawoływaniem do składania protestów. Poniżej przykład takiego protestu, w którym pozbierano wyniki różnych analiz.
Ogólnie wyglądało to mało profesjonalnie: powklejane fragmenty analiz niewiadomego pochodzenia, na przykład zrzuty ekranu z arkusza Excel (na dodatek z dzieleniem przez zero).

Merytorycznie było niewiele lepiej, większość argumentów zupełnie nie miała sensu, na przykład że pierwsze cyfry liczby oddanych głosów na Nawrockiego w komisjach nie rozkładają się zgodnie z tak zwanym prawem Benforda.
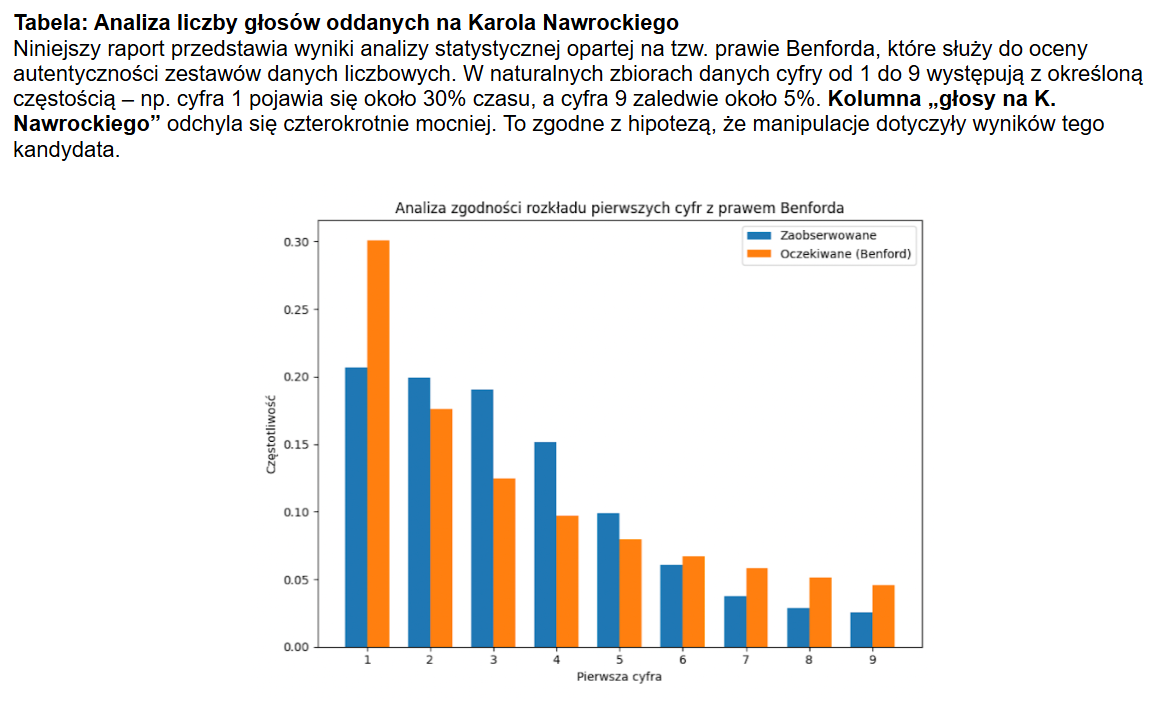
Powoływanie się na to prawo jest ogólnie dość naciągane, bo muszą być spełnione założenia, które bardzo trudno uzasadnić. Natomiast w tym konkretnym przypadku, ponieważ wielkości komisji są dość zbliżone, NA PEWNO założenia nie są spełnione.
Problem w tym, że niski poziom tych analiz był oczywisty tylko dla osób, które znają się na statystyce. A takich osób nie jest dużo.
Link do tego protestu umieścił we wpisie na X Cezary Tomczyk, wiceprzewodniczący KO. Zachęcał do składania protestów i twierdził, że komitet wyborczy Trzaskowskiego też go złoży.
Ponieważ sprawa wydawała mi się poważna, opublikowałem artykuł o błędach w analizach, na które powoływano się w proteście.
Krzysztof Kontek
Oprócz tego typu kiepskich analiz pojawiły się też takie, które przynajmniej na pierwszy rzut oka wydawały się profesjonalne – i to nawet osobom, które znają statystykę. Najpopularniejszą była analiza dr. Kontka. Naciągając statystykę do granic możliwości, pokazał on, że nieprawidłowości w komisjach było tak dużo, że mogły zniwelować różnicę w liczbie głosów między kandydatami.

O “zjawisku dr. Kontka” można by napisać osobny artykuł. Jeśli ktoś śledził jego wpisy na X, zapewne trudno mu było zrozumieć, jak to się stało, że tak wiele osób uwierzyło w jego analizy.
(W ostatnim z powyższych wpisów dr Kontek pomylił mnie z prof. Bieckiem i z jego wpisem na linkedin).
Sprawa zrobiła się naprawdę poważna. W pewnym momencie z badań opinii publicznej wynikało, że mniej więcej połowa Polaków chce ponownego przeliczenia głosów (choć trzeba dodać, że chęć ponownego przeliczenia nie jest tożsama z tym, że ktoś uważa, że wybory zostały sfałszowane).
Prokurator Generalny uwierzył dr. Kontkowi i zlecił ponowne przeliczenie głosów w prawie półtora tysięca komisji, twierdząc, że istnieje w nich wysokie prawdopodobieństwo nieprawidłowości.

Raport
Napisałem artykuł krytykujący analizę dr. Kontka oraz zaproponowałem swój model wskazujący na komisje, w których najprawdopodobniej podano złe wyniki (bardziej zaawansowany niż analiza, którą opublikowałem wcześniej). Z modelu wynikało, że po pierwsze takich komisji jest niewiele, po drugie jest w nich symetria, tzn. błędy się znoszą.
Ostatecznie analizy te stały się częścią raportu napisanego wspólnie z dr. hab. Dominikiem Batorskiem i dr. hab. Jarosławem Flisem, opublikowanego przez Fundację Batorego.

Opinie biegłych
Okazało się, że kilka dni wcześniej Prokurator Generalny powołał biegłych, dr. hab. Jacka Hamana i dr. hab. Andrzeja Torója, i mniej więcej w tym samym czasie, w którym opublikowano nasz raport, ukazały się ich opinie. Zaproponowali w nich swoje modele, podobne do tego przedstawionego w raporcie, z praktycznie tymi samymi wnioskami.

Posiedzenie Sądu Najwyższego
Na opinie biegłych oraz raport Fundacji Batorego powoływano się w Sądzie Najwyższym na rozprawie dotyczącej stwierdzenia ważności wyborów.

Trudno uwierzyć, jak daleko to zaszło. W Sądzie Najwyższym dyskutowano o modelu regresji liniowej, czym jest prawdopodobieństwo i co da się wykazać przy pomocy statystyki.
(Powszechnie dyskutowane kwestie, czy jest to Sąd, nie-Sąd itp., leżą daleko poza moimi kompetencjami i zainteresowaniami).
Model detekcji anomalii wyborczych w wyborach prezydenckich
Przejdę teraz do skrótowego i możliwie przystępnego omówienia, jak przy pomocy modelu statystycznego można wykryć komisje, w których z dużym prawdopodobieństwem popełniono błędy. Jeśli Czytelnik zna statystykę, odsyłam do pełnego opisu. Udostępniam też kod w języku R, gdyby ktoś chciał odtworzyć moje wyniki.
Zastosowane przeze mnie podejście jest dobrze znane w statystyce i w gruncie rzeczy proste. Trudniejsza jest dyskusja, na ile można takiemu modelowi zaufać, co da się z niego wywnioskować z dużą pewnością, a czego lepiej w ogóle nie robić. Dochodzi też kwestia odpowiedzialności, w końcu to sprawa wagi państwowej. Poza tym nie jest to jedynie sprawa wykonania jak najlepszej analizy statystycznej, ale równie ważne jest, w jaki sposób się ją opisze, jakich dokładnie słów użyje – mając na uwadze, że wnioski z takiej analizy będą wyciągać osoby, które nie są statystykami.
Główne cele budowy takie modelu to:
- Identyfikacja komisji, w których wynik drugiej tury jest podejrzany, z dużym prawdopodobieństwem błędny.
- Odpowiedź na pytanie, czy rzeczywisty wynik wyborów mógł być inny, zakładając, że w wytypowanych komisjach rzeczywiście doszło do błędów
W tym miejscu warto wyraźnie napisać, czym jest “wynik wyborów”. Otóż formalnie jest to stwierdzenie, który z kandydatów otrzymał więcej ważnych głosów — a nie ile ich otrzymał. Jest to istotne, bo po pierwsze, dokładnej liczby głosów zwyczajnie nie da się poznać (przynajmniej w obecnej formie ich liczenia). Wystarczy jedno błędne zakwalifikowanie głosu nieważnego jako ważny, a to praktycznie musi się wydarzyć przy tak dużej liczbie oddanych głosów. Po drugie, taka definicja daje nam pewien “bufor”. Jeśli oszacujemy, że w wyniku błędów jeden z kandydatów otrzymał za dużo głosów o X, to jeśli X jest znacznie mniejsze od różnicy między kandydatami, wynik wyborów jest znany.
Bezwładność preferencji wyborczych
Jak szukać komisji z dziwnymi wynikami? Na poniższym wykresie zestawiono procent głosów, jakie otrzymał Trzaskowski w drugiej turze (oś Y) oraz w pierwszej (oś X). Jeden punkt to jedna komisja i na potrzeby wykresu ograniczyłem się tylko do takich, w których zagłosowało co najmniej 500 osób (w ostatecznym modelu uwzględniłem też mniejsze komisje). Ponieważ w pierwszej turze było więcej kandydatów, to licząc procent głosów, brałem pod uwagę tylko wyniki Nawrockiego i Trzaskowskiego. Na przykład, niezależnie od tury, 50% oznacza, że Trzaskowski otrzymał tyle samo głosów co Nawrocki.
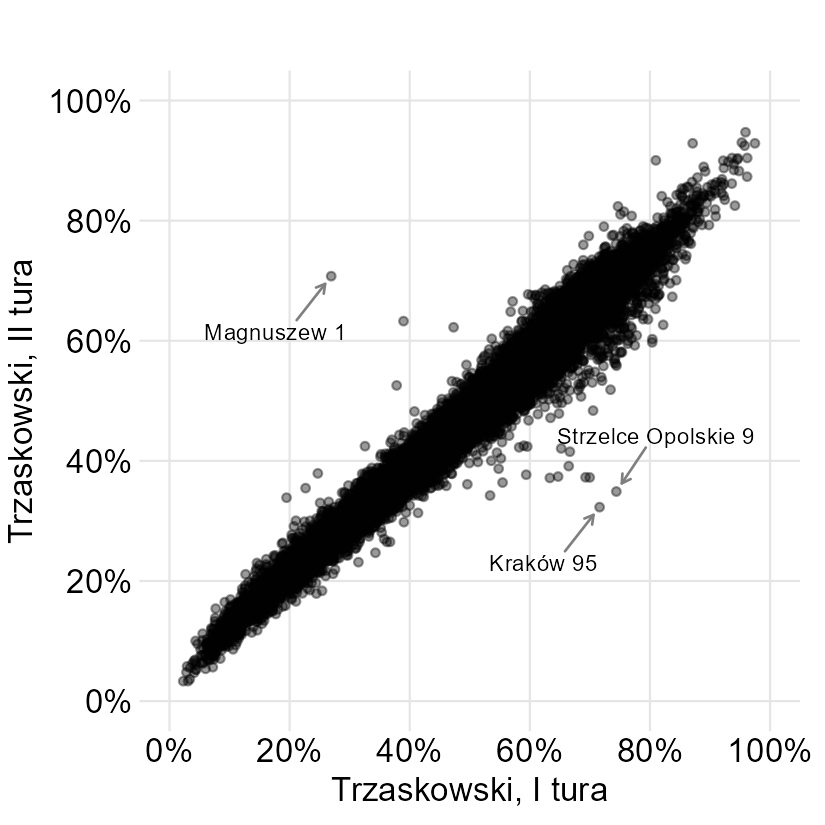
Na wykresie widać ogromną bezwładność: ludzie zmieniający preferencje między pierwszą a drugą turą to rzadkość. Wyniki drugiej tury, i to w prawie każdej komisji poza najmniejszymi, łatwo przewidzieć na podstawie pierwszej tury.
Oprócz tego widać komisje, w których wynik drugiej tury zupełnie nie pasuje do pierwszej. Jedną z nich jest komisja w Krakowie, o której pisałem wcześniej: Trzaskowski otrzymał tam znacznie mniej głosów, niż “powinien”. Po drugiej stronie mamy komisję w Magnuszewie, w której to Trzaskowski dostał za dużo.
To podejście można rozszerzyć, wykorzystując wyniki wszystkich kandydatów, jak również dodatkowe informacje (np. głosy nieważne, frekwencję, ile osób głosowało z zaświadczeniem). Odpowiednim narzędziem jest tzw. regresja liniowa. Pozawala ona dokładniej przewidzieć wyniki drugiej tury, a przez to z większą pewnością wskazać komisje z błędnymi wynikami.
Wyniki modelu
Jeśli na podstawie modelu wiemy, jak “powinien” wyglądać wynik drugiej tury, możemy go porównać z tym, co podała komisja. Oczywiście to nie będzie się dokładnie zgadzać, pewne różnice są naturalne. Istnieją jednak takie, których zwyczajnie nie da się wytłumaczyć – i wiara w to, że tak się po prostu złożyło (np. połowa wyborców zmieniła poglądy) jest naiwnością.
Bazując na teorii statystyki, jesteśmy w stanie mniej więcej wskazać granicę: jakie różnice są spodziewane i nie świadczą o błędach, a jakie są zbyt nieprawdopodobne. Wskazałem 97 anomalii: w 50 z nich potencjalny błąd był na korzyść Trzaskowskiego, w 47 na korzyść Nawrockiego. Trzaskowski stracił przez to szacunkowo 1051 głosów, Nawrocki tyle zyskał. Różnica między nimi (369591 głosów) powinna być mniejsza o 2102 głosy.
Dla porównania, stosując identyczne podejście do wyborów z 2020 roku, wykryłem 109 anomalii: 49 na korzyść Trzaskowskiego, 60 Dudy. Trzaskowski stracił 291 głosów. W 2015 roku było 50 anomalii: 18 na korzyść Komorowskiego, 32 Dudy. Komorowski stracił 868 głosów.
Poza minimalnym wpływem na ostateczny wynik ważna jest tutaj symetria: w przybliżeniu tyle samo błędów na korzyść obu kandydatów. Jeśli założyć, że źródłem tych niepoprawnych wyników są przypadkowe błędy członków komisji (a nie celowe działanie), właśnie tak powinno to wyglądać.
Ocena poprawności podejścia
Nadarzyła się dość niespodziewana dla mnie okazja, by ocenić dokładność opisywanej metody. W 250 komisjach jeszcze raz policzono głosy

W najlepszej sytuacji był dr hab. Jacek Haman, bo prokuratura wybrała komisje, opierając się na jego modelu. Ale ponieważ mój był bardzo podobny, to większość wskazanych przeze mnie komisji znalazła się w zbiorze 250 przeliczonych.
Trzeba tu od razu dodać, że taka ocena jest tylko częściowo możliwa, bo zostały przeliczone jedynie komisje, w których z dużym prawdopodobieństwem popełniono błędy. Do pełnej oceny potrzebna byłaby na przykład próba losowa 100 komisji, żeby sprawdzić, czy w tych niewskazanych przez model rzeczywiście wyniki były poprawne. Natomiast w drugiej części artykułu wyjaśniam, dlaczego taki test – mimo że przydatny – nie jest konieczny. Oprócz tego za pewne przybliżenie próby losowej można potraktować niewielkie komisje, które raczej niepotrzebnie wskazał dr Haman (w prawie wszystkich wyniki okazały się poprawne).
Z 97 komisji, które wytypowałem, ponownie przeliczonych zostało 75 (tzn. znalazły się też na liście dr. Hamana). W 46 z nich rzeczywiście wystąpiły błędy, w pozostałych wyniki były prawidłowe z dokładnością do trzech głosów. Przeoczyłem 17 komisji, w których wystąpiły błędy.
Dlaczego te komisje nie zostały wykryte? Jest to kwestia przyjęcia granicy, od której traktujemy wynik w komisji jak anomalię. We wszystkich przypadkach poza jednym były one bardzo blisko tej granicy, czyli można je było traktować jako “podejrzane”. Ten jeden przypadek to komisja, w której pomylono się o 25 głosów i model dr. Hamana też go nie wykrył. Co więcej, ta komisja nie była nawet na granicy, tzn. z obu modeli wynikało, że wyniki drugiej tury pasują do pierwszej. W takim razie musiała zostać przeliczona z innego powodu (być może ktoś z komisji zorientował się, że wyniki były złe). To oczywiście oznacza, że w niezbadanych komisjach może być więcej takich z błędami. Jeszcze do tego wrócę.
Dokładność modelu
Ocena modelu poprzez weryfikację, jak dużo rzeczywiście niepoprawnych wyników zostało przy jego pomocy wskazanych, mimo że wydaje się naturalna, nie jest wystarczająca. W szczególności, jeśli okazałoby się, że we wszystkich wytypowanych komisjach są błędy, to świadczyłoby to o tym, że model NIE był dobry. Im bliżej przyjętej granicy znajduje się komisja (mniejsza różnica między przewidywanym wynikiem a oficjalnie podanym), tym mniejsze prawdopodobieństwo, że wystąpił w niej błąd – więc w części z nich tego błędu nie powinno być.
To można mniej więcej zweryfikować na podstawie danych, choć nie jest łatwo określić, czy obserwowane tempo spadku jest właściwe. Natomiast można zrobić coś innego – i moim zdaniem jest to najlepszy sposób oceny poprawności modelu w tym konkretnym problemie. Otóż sam model nie tyle typuje komisje (jest to tylko jedno z jego zastosowań), ale szacuje, jaki powinien być w nich poprawny wynik. Z ogólnych charakterystyk modelu wiemy, że robi to bardzo dobrze. Pytanie, czy również w komisjach, w których wyniki były błędne? Oczywiście nie, jeśli spojrzymy na oficjalne wyniki – bo są błędne! A jak to będzie wyglądać, jeśli poprawimy je, bazując na danych z ponownego przeliczenia?
Na poniższym wykresie zaznaczyłem komisje, które wskazał mój model i w których okazało się, że wyniki były błędne. Na osi X podano, ile powinien otrzymać Trzaskowski według modelu, a na osi Y ile oficjalnie otrzymał.
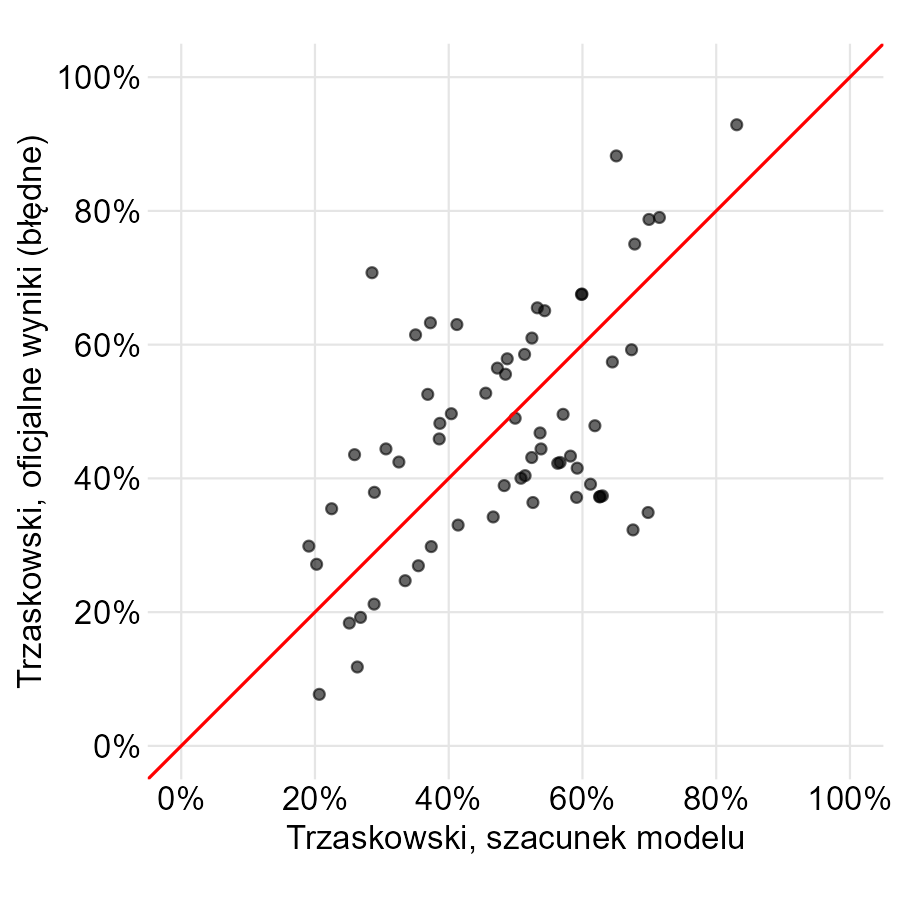
Jeśli model byłby idealny i wyniki poprawne, wszystkie powinny układać się wzdłuż czerwonej linii. Tak oczywiście nie jest, bo wiemy, że te konkretne wyniki nie są poprawne. Wprowadźmy jednak na osi Y wyniki z ponownego przeliczenia.
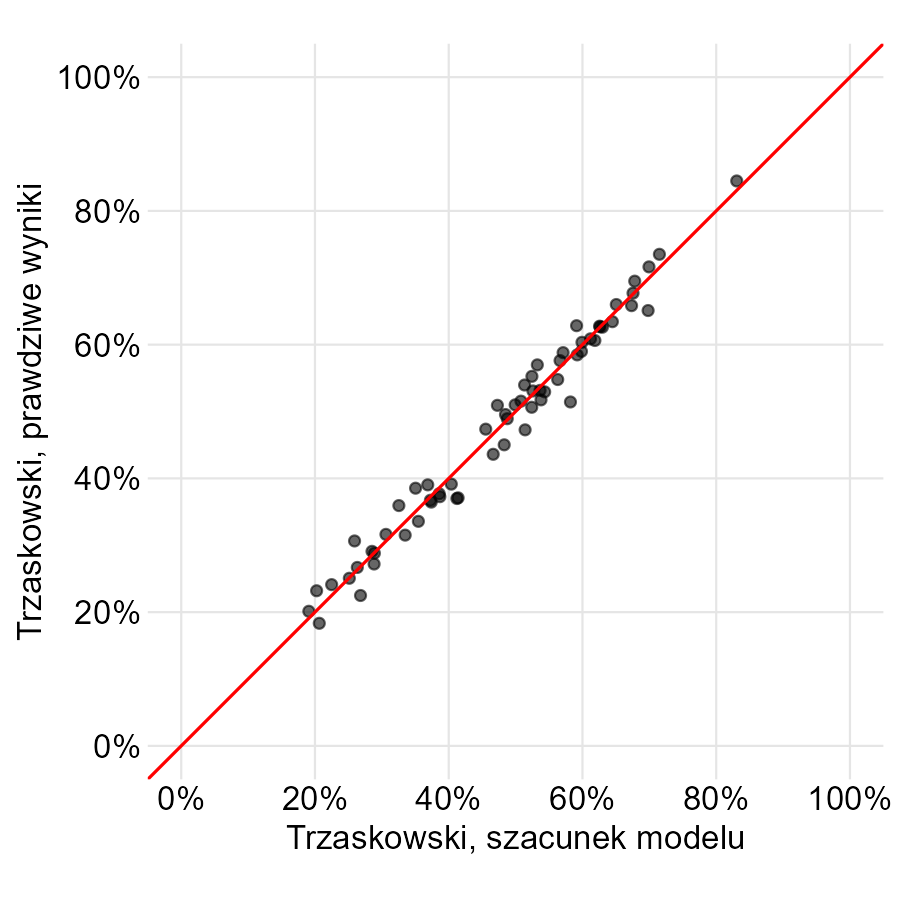
Zgodność jest prawie idealna. Model działa.
Co bardzo ważne, tzw. kalibracja modelu również jest prawie idealna. Model mógłby być dokładny (np. mylić się średnio o dwa punkty procentowe), ale zawsze na korzyść jednego z kandydatów. To byłoby niepokojące, bo oznaczałoby, że faworyzuje jednego z kandydatów we wskazywaniu błędów: częściej granicę przekroczą komisje, w których ten kandydat przegrał. Taka sytuacja nie występuje, niedokładność jest symetryczna.
Z tego płynie jeszcze jeden bardzo ważny wniosek. Przyjęcie takiej a nie innej granicy (ile komisji sprawdzamy), mimo że oparte na statystyce, zawsze będzie kwestią dyskusyjną. Możemy jednak sprawdzić w danych, co by było, gdyby tę granicę przesunąć i wytypować np. 1000 komisji. Takie analizy wykonałem (biegli również) i wynikało z nich, że nawet jeśli w znacznie większej liczbie komisji byłyby błędy, to występuje w nich symetria (mniej więcej tyle samo traci Trzaskowski i Nawrocki), przez co ostateczny wynik wyborów, czyli kto wygrał, pozostaje bez zmian. Jedyne wątpliwości, jakie można by mieć, to czy model jest odpowiedni, w szczególności nie faworyzuje jednego z kandydatów. I zaprezentowany wyżej wykres w mojej ocenie rozwiewa te wątpliwości.
Jakie fałszerstwa da się wykryć?
A jakie są możliwości takich modeli? Jakie fałszerstwa jesteśmy w stanie wykryć? Możemy to zbadać, sami wprowadzając fałszerstwa i próbując je wykryć.
Bazowałem na wynikach z 2020 roku, bo co do nich nie było wątpliwości. Rozważałem wiele scenariuszy, np. losowałem 100 komisji, w których wprowadzałem fałszerstwa tylko na korzyść jednego kandydata – bo pojawiły się zarzuty, że nie wykryjemy takich asymetrycznych przypadków (miało to wynikać z technicznego faktu, że suma wszystkich reszt w regresji jest równa zero). W rzeczywistości wykrycie czegoś takiego nie sprawia żadnej trudności.
Zarzucono również, że przy pomocy takiego podejścia znajdziemy jedynie ekstremalne przypadki, a nie np. niewielkie, ale systematyczne oszustwa. Wprowadzałem fałszerstwa na poziomie trzech punktów procentowych na rzecz jednego kandydata w 5 tys. komisji (żeby mogły wpłynąć na ostateczny wynik, musi być ich dużo). Takich przypadków nie da się wykryć punktowo (nie wskażemy konkretnych komisji z błędami), ale problem jest widoczny w tzw. rozkładzie reszt, który jest wyraźnie asymetryczny (domyślam się, że jeśli Czytelnik nie zna statystyki, jest to dość enigmatyczne).
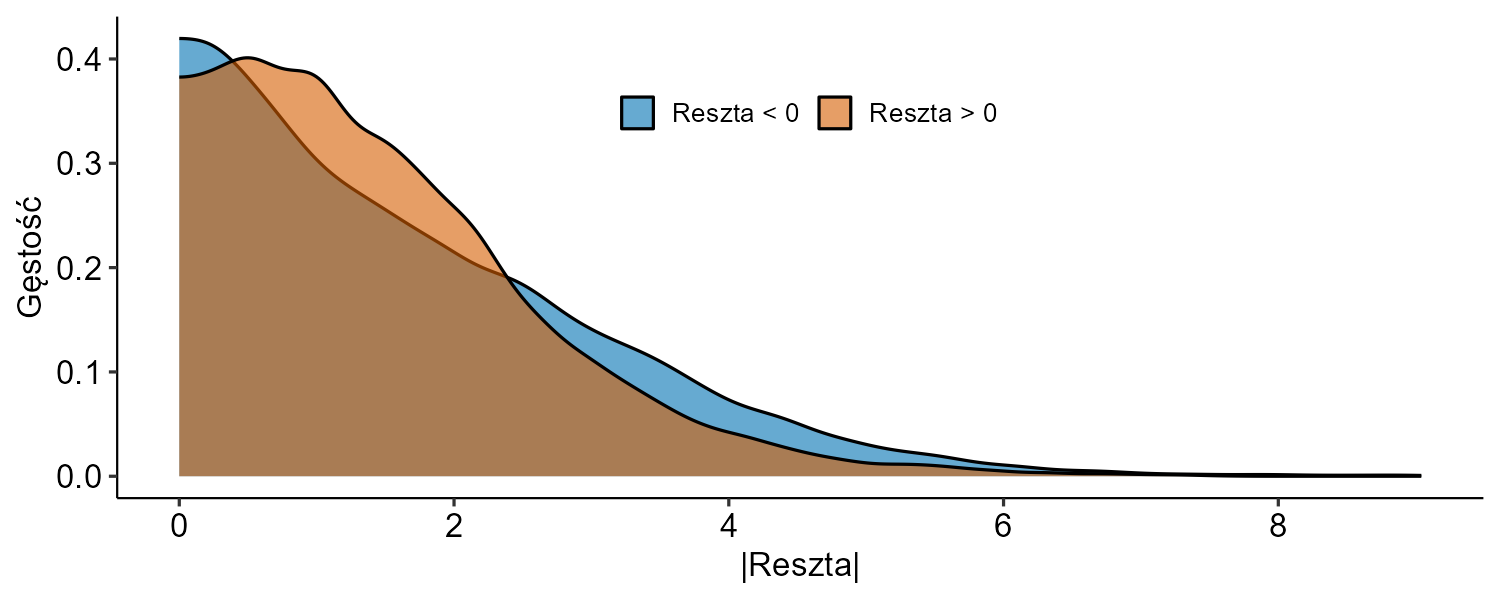
Zarzuty
Pojawiły się też inne zarzuty, na przykład taki, że skoro w 250 zbadanych komisjach błędy pojawiły się w 1/3 lub 1/4 (zależy, jak liczyć pomyłki o 1-2 głosy), to gdyby sprawdzić wszystkie, tych błędów byłoby bardzo dużo. Oczywiście takie wnioskowanie miałoby sens tylko wtedy, gdyby zbadano 250 przypadkowych komisji, a nie takich, które zostały wskazane przez model.
Co prawda nie powinniśmy oczekiwać, że w niezbadanych komisjach nie będzie żadnych błędów, natomiast nie może być tak, że model świetnie działa dla tych 250 zbadanych komisji (poprawnie szacuje prawdziwą liczbę głosów), a nie radzi sobie w pozostałych. Drugą stroną faktu, że udało się wskazać błędne komisje oraz z bardzo dużą dokładnością podać w nich liczbę głosów, jest to, że w niewskazanych komisjach tych błędów jest niewiele. A jeśli już są, to różnica między podaną a poprawną liczbą głosów jest niewielka (bo gdyby było inaczej, taka komisja zostałaby wykryta). We wspomnianym wcześniej artykule staram się oszacować, jak dużo może być błędów w niezbadanych komisjach.
Odpowiedź na inne zarzuty można znaleźć tutaj.
Czy znamy wynik wyborów?
W statystyce, gdy próbujemy udowodnić jakąś hipotezę, procedura zwykle wygląda tak, że stawiamy tak zwaną hipotezę zerową, którą następnie atakujemy, zbierając dowody przeciw niej. Jeśli uda się zebrać wystarczające, odrzucamy ją i przyjmujemy hipotezę alternatywną, zwykle przeciwną do zerowej. To podejście jest popularne również poza statystyką. Na przykład w sądownictwie hipotezą zerową jest niewinność oskarżonego (nazywamy to domniemaniem niewinności). Jeśli nie zbierzemy wystarczających dowodów, pozostaje ona w mocy (w statystyce mówimy, że nie mamy podstaw do jej odrzucenia).
W przypadku wyborów taką hipotezą zerową jest ich uczciwość. I bazując na przedstawionych analizach, brak jest argumentów, żeby tę hipotezę odrzucić. Na pytanie, czy znamy wynik wyborów, można odpowiedzieć: nie mamy podstaw, by uważać, że nie znamy.
Zauważmy, że z tego nie wynika, że hipoteza zerowa jest prawdziwa. Wypowiadamy jedynie zdanie negatywne: nie mamy podstaw, by coś twierdzić. Brak jest dowodów uzasadniających skazanie oskarżonego – więc tego nie robimy – ale w rzeczywistości może być winny.
Są jednak sytuacje, w których można powiedzieć coś więcej. Jeśli atakujemy hipotezę z wielu stron i ona cały czas te ataki odpiera, prawdopodobieństwo jej prawdziwości jest coraz większe. W przypadku wyborów tych ataków było bardzo dużo. Pojawiało się wiele analiz, w których przypatrywano się różnym aspektom tego problemu, choćby związkom z nieważnymi głosami, ze składami komisji itd. Co ważne, analizy te wykonało niezależnie wielu badaczy, dochodząc do tych samych wniosków: nie ma nic, co wskazywałoby na to, że wybory zostały sfałszowane. Dlatego moim zdaniem można wypowiedzieć zdanie twierdzące. Tak, znamy wynik wyborów: Nawrocki otrzymał więcej głosów niż Trzaskowski.
Czy da się odwrócić głosy?
Na koniec ciekawostka. Otóż pojawiło się sporo opinii, że odwrócenie głosów w komisji (przypisanie ich złemu kandydatowi) jest niemożliwe przypadkiem. Że przecież członkowie komisji mają tylko dwie liczby do wpisania i nie da się przy tym pomylić. Zobaczmy zatem, jak poradziła sobie prokuratura.
Gdy przeliczyła głosy jeszcze raz w 250 komisjach, udostępniła arkusz z nowymi wynikami. Poniżej fragment tego arkusza z wynikami dla pięciu komisji: po lewej stronie pierwotne, po prawej korekta po ponownym przeliczeniu.
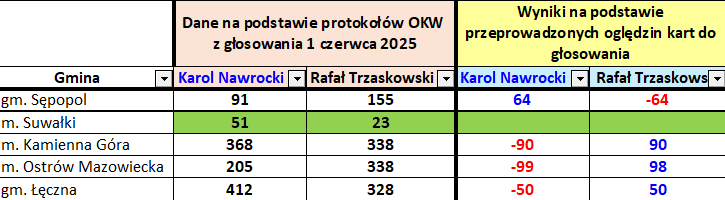
W gminie Sępopol Nawrocki powinien otrzymać 64 głosy więcej, niż wynikałoby z ogłoszonych wyników. Zauważmy, że jak do 91 dodamy to 64, otrzymamy 155, czyli wynik Trzaskowskiego. Jest to przypadek, w którym głosy policzono poprawnie, ale odwrócono je przy podawaniu. Dalej, w Suwałkach wszystko było w porządku. Kamienna Góra to ciekawy przypadek: różnica między Nawrockim i Trzaskowskim to 30 głosów, ale pomylono się aż o 90. Czyli to nie jest sytuacja, w której odwrócono głosy, ale po prostu część z nich błędnie zaliczono Nawrockiemu. To zwiększa prawdopodobieństwo, że w tej konkretnej komisji mamy do czynienia z fałszerstwem, a nie pomyłką, choć wciąż da się to wyjaśnić, szczególnie że 90 jest podzielne przez 10. Jak liczy się głosy, to często grupuje się je po 10 – i zapewne po przeliczeniu ktoś położył je w miejscu, w którym leżały głosy oddane na innego kandydata (choć nie da się wykluczyć, że zrobiono to celowo).
Spójrzmy jednak na komisje w Ostrowi Mazowieckiej i Łęcznej. Jak widzimy, Nawrocki otrzymał tam za dużo głosów. Problem w tym, że te komisje zostały wskazana jako te, w których to Trzaskowski dostał za dużo. Czyli z analiz wynikało, że była tam anomalia w jedną stronę, a okazało się, że jest w drugą. Jest to kompletnie nieprawdopodobne.
Powód mógł być tylko jeden: prokuratura odwróciła głosy. I po dwóch tygodniach pojawiła się aktualizacja arkusza z poprawionymi wynikami.

Zauważmy, że nie tylko wyniki są odwrotne, ale jeszcze różnią się o parę głosów!


