Wykres to jedno z podstawowych narzędzi do odnajdywania wzorców w danych i prezentacji wyników analiz. Warto odróżnić te dwa zastosowania. Jeśli wykresy wykonujemy dla siebie, jako część procesu analizy danych, nie musimy przywiązywać do nich aż tak dużej wagi. Bo po pierwsze, zapewne znamy się na swojej robocie i nawet jeśli wykres sugeruje większe zależności, niż są w rzeczywistości (bo np. oś Y nie zaczyna się w zerze), raczej będziemy tego świadomi. Po drugie, jeśli zrobimy wykres niepoprawnie i wyciągniemy złe wnioski, to liczba osób, która zostanie wprowadzona w błąd, jest zwykle mocno ograniczona.
Sprawa wygląda inaczej, gdy wykres pojawia się w raporcie, prezentacji, portalu społecznościowym czy telewizji. Powinniśmy zadbać o to, by był on zgodny ze sztuką. Czyli w skrócie: był wiarygodnym (uczciwym) podsumowaniem wykrytych przeze nas zależności. Jeśli z danych wynika, że coś wzrosło dwukrotnie, wykres nie może sugerować, że czterokrotnie.
Niestety, nie jest trudno znaleźć przykłady wykresów, które nie są spójne z danymi. Tu znów warto wyróżnić dwa przypadki:
- Autor wykresu nie ma odpowiednich umiejętności.
- Autor wykorzystuje swoje umiejętności, żeby manipulować odbiorcą, na przykład „podkręcając” pewne różnice, które tak naprawdę są niewielkie.
W obu przypadkach wykresy wprowadzają w błąd, więc są szkodliwe, choć groźniejsza jest oczywiście druga sytuacja. Można powiedzieć, że jeśli ktoś się nie zna, będzie popełniał błędy „losowo”, przez co czasem zawyży różnice, czasem zaniży. W drugim przypadku działanie jest kierunkowe.
Motywacją plebiscytu na najgorszy wykres jest uodpornienie nas na takie manipulacje poprzez pokazanie konkretnych przykładów. Być może dzięki temu „sprzedawcy nieprawd” będą mieli trudniejsze zadanie.
Wyniki poprzedniej edycji: https://danetyka.com/najgorszy-wykres-2024/
Zasady plebiscytu
Z nadesłanych wykresów wybrałem 16 kandydatów, na których można było głosować w czterech ankietach (półfinałach) na Linkedin. Zwycięzcy każdego z półfinałów spotkali się wielkim finale. Pierwsze miejsce zajął wykres nr 15 („Ucieczki więźniów”), drugie miejsce nr 4 („Super Express”), trzecie nr 9 („Polska – Grecja”). W sumie w pięciu ankietach oddano 1755 głosów.
Poniżej prezentacja wszystkich wykresów. Starałem się wypunktować, co jest w nich złego oraz jak można je poprawić. Częściowo jest to subiektywne, bo mówimy tu o tym, jakie wrażenie powinien mieć odbiorca, patrząc na wykres – a to zależy też od odbiorcy. W większości jednak są to klasyczne błędy, znane od lat.
Każdy z wykresów został gdzieś opublikowany, zwykle w polskich mediach. Nie podaję odnośników, bo celem plebiscytu nie jest krytyka autorów.
Wykres 1
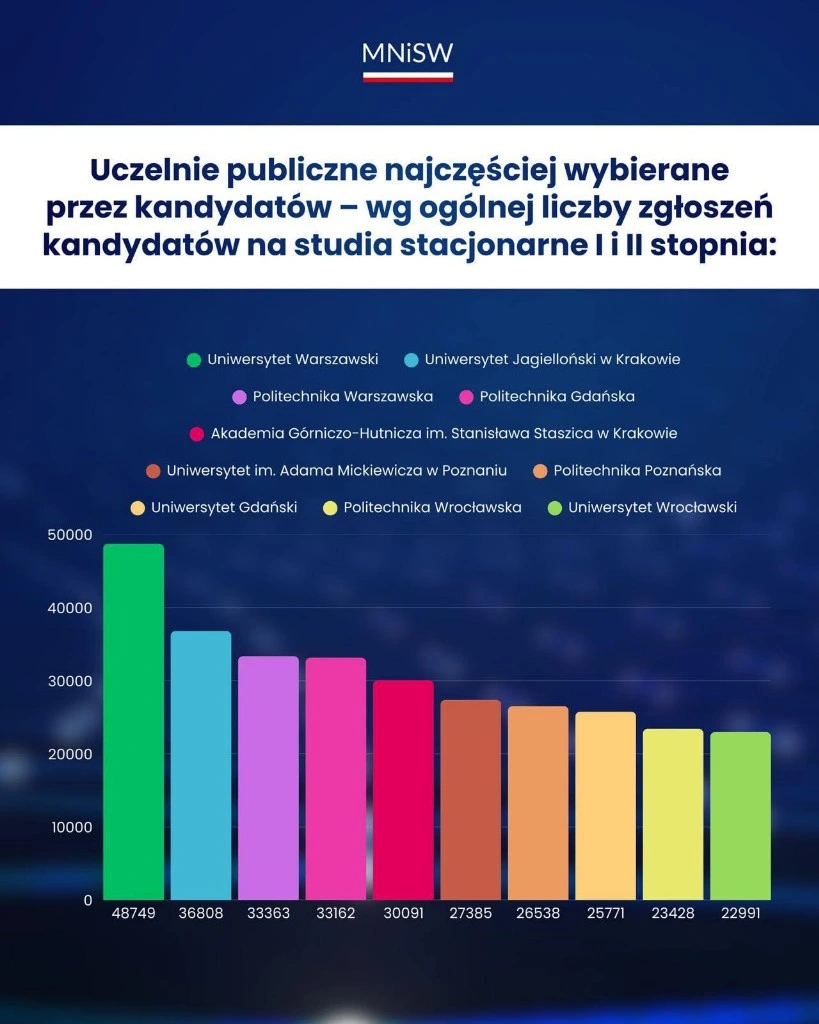
Zaczynamy od wykresu słupkowego z dość specyficznymi etykietami na osi X. Zamiast nazw uczelni pojawiają się tu dokładne wartości z osi Y. Domyślam się, że autorzy mieli problem z długimi nazwami, ale trudno o gorsze rozwiązanie. Całe szczęście, że kolejność w legendzie odpowiada tej na osi X, inaczej ciężko byłoby stwierdzić, który słupek odpowiada na przykład Politechnice Wrocławskiej, a który Uniwersytetowi Gdańskiemu (bardzo podobne kolory).
Jak to zrobić lepiej? Często w takich sytuacjach wystarczy odwrócić wykres o 90 stopni, wtedy mamy więcej miejsca na etykiety. W przypadku najdłuższych nazw użyłem skrótowców AGH i UAM, bo jest jasne, co oznaczają. Wartości podałem w tysiącach, żeby nie zmuszać odbiorcy do liczenia zer.
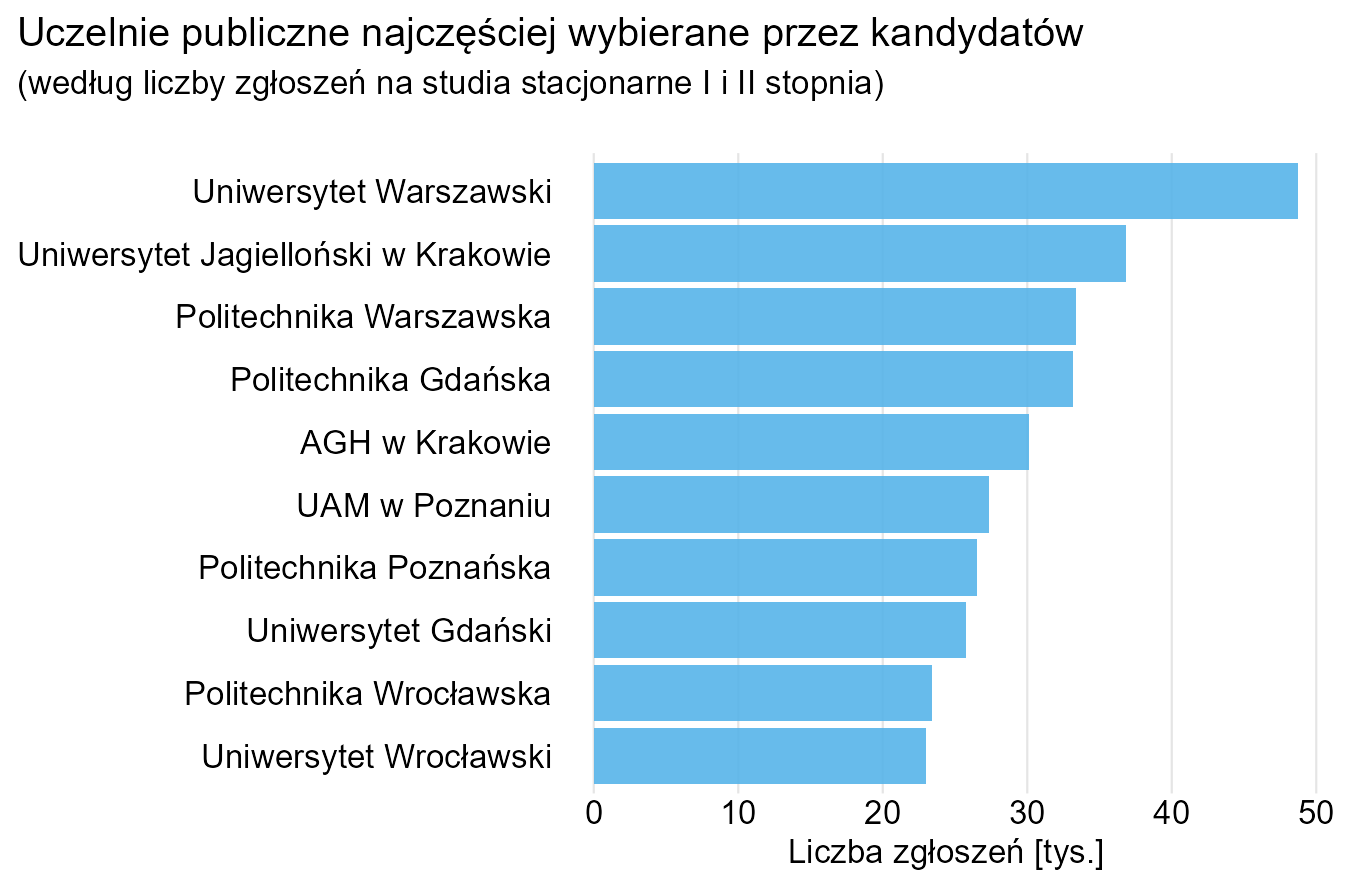
Jeśli chcemy, możemy dodać etykiety z wartościami liczbowymi, choć nie ma potrzeby, żeby podawać je aż tak dokładnie (np. wystarczy 23 tys. zamiast 22991). Zauważmy, że teraz nie są potrzebne kolory – i to jest ZALETA takiego przedstawienia. W sztuce tworzenia wykresów kolor to kolejny „wymiar”. Używamy go, gdy chcemy przedstawić dodatkową informację (np. podział na politechniki i uniwersytety, uczelnie publiczne i niepubliczne itp.)
Wykres 2

PKB Polski bardzo wyraźnie wzrosło w ostatnich latach, ale niekoniecznie w takim stopniu, jak na powyższym obrazku. Co tu się wydarzyło? PKB wzrosło ponad pięć razy (z 175 mld dolarów do 915 mld), ale autorzy wykresu zwiększyli OBA wymiary (długość i szerokość) pięciokrotnie. Tym samym pole wzrosło ponad 25-krotnie i takie wrażenie będzie miał odbiorca.
Jak to poprawić? Cóż, najlepiej w ogóle zrezygnować z takiej metody prezentacji danych. Zauważmy, że powierzchnia Polski i Szwecji jest zupełnie inna, a przez to ciężko zrobić to dobrze. Poniżej propozycja, jak to pokazać inaczej.
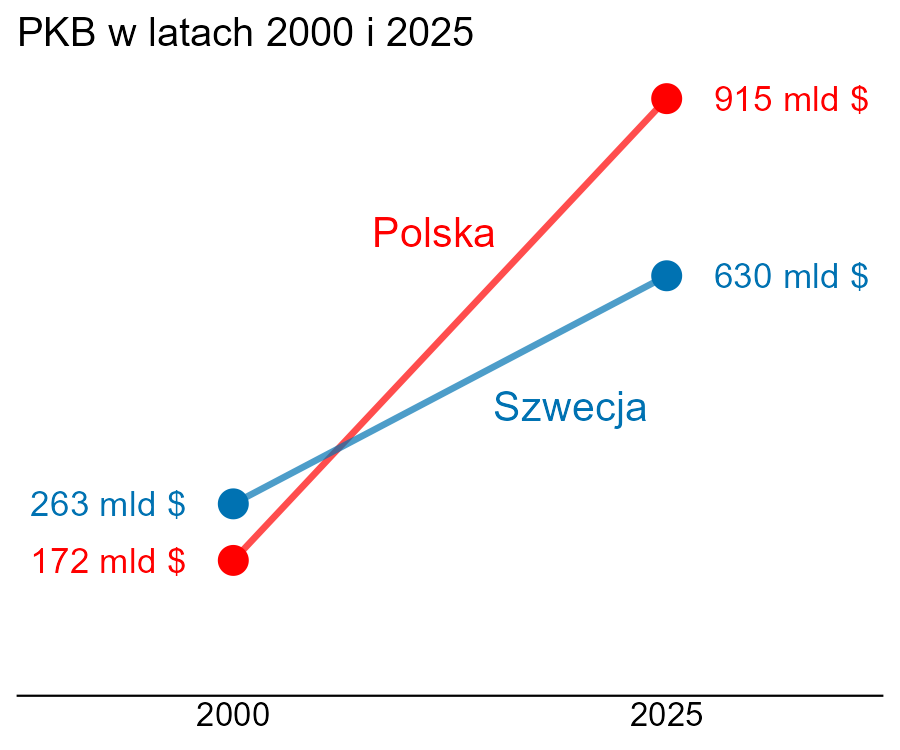
Przy okazji warto wspomnieć, że wykres spotkał się z mocną krytyką na portalach społecznościowych, ale najczęściej niesłuszną. Zarzucano mu, że przecież w Szwecji żyje znacznie mniej ludzi, więc takie porównanie nie ma sensu. Zamiast tego powinno się podać PKB per capita, czyli dzielone przez liczbę mieszkańców. Ale liczby mieszkańców zmieniły się nieznacznie między latami 2000 i 2025, a wykres pokazuje głównie WZROST PKB, a nie same wartości. Nie ma znaczenia, czy podzielimy je przez stałą (nawet jeśli będzie różna dla Polski i Szwecji), względny wzrost będzie taki sam. Oprócz tego, w niektórych zastosowaniach to SUMA (czyli PKB) może mieć większe znaczenie od ŚREDNIEJ (PKB per capita).
Wykres 3
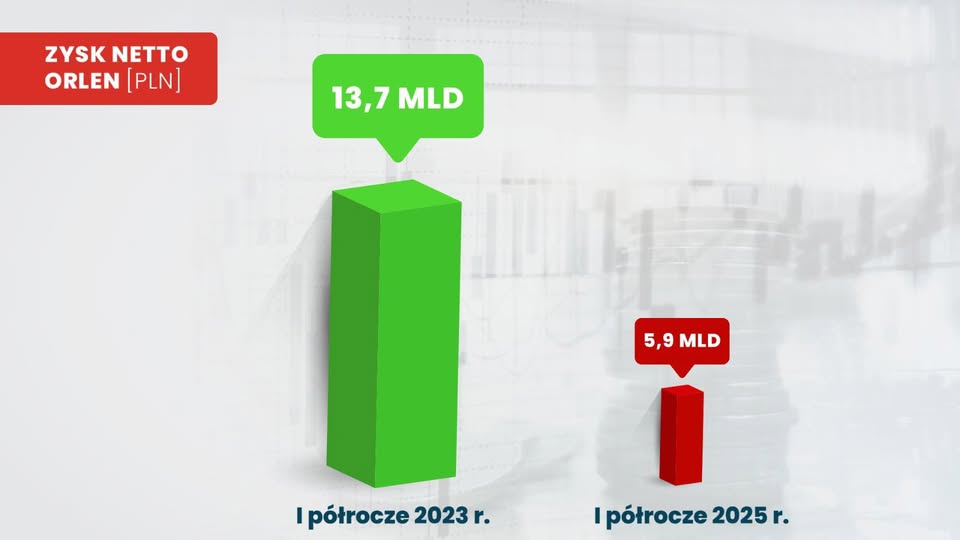
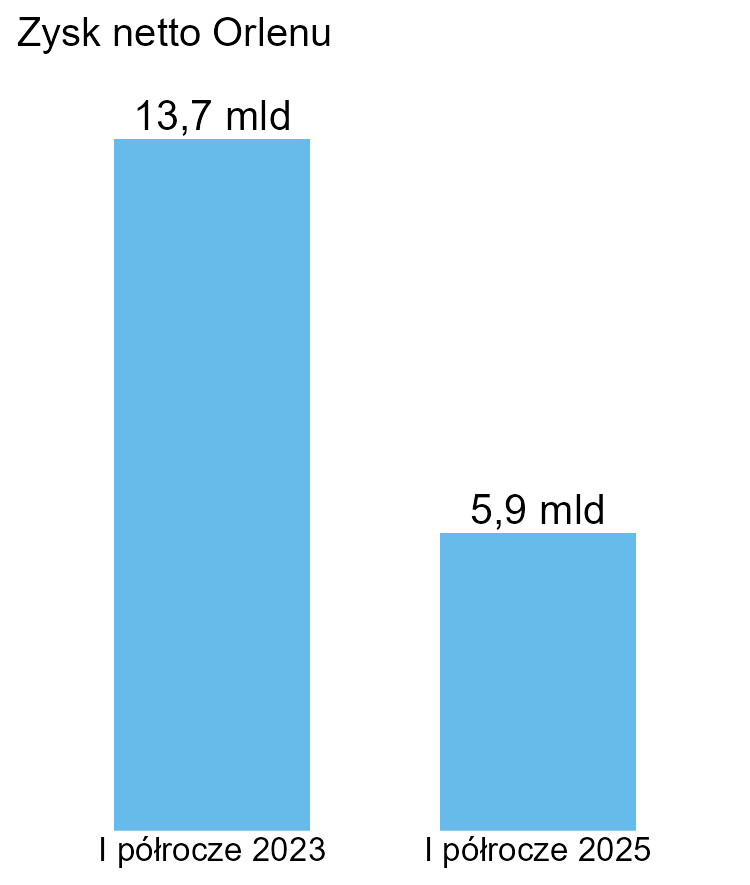
To wręcz książkowy przykład manipulacji. Różnica między 13,7 mld a 5,9 mld najwyraźniej była za mała i trzeba było dodatkowo zaznaczyć to kolorem oraz wymiarami słupków. W poprzednim wykresie (PKB Polski) zwiększyły się dwa wymiary, a tu aż trzy, na dodatek wysokość trzykrotnie, mimo że 13,7 jest tylko 2,36 razy większe od 5,9.
Oczywiście cel tego wykresu jest propagandowy. Można go też potraktować jako rodzaj plakatu, który rządzi się swoimi prawami. Czy w takim razie warto to piętnować? A czy gdyby zamiast 13,7 mld pojawiło się tutaj 23,7 mld, to uważalibyśmy, że wszystko jest w porządku? Raczej oczekujemy, że podane liczby są prawdziwe – a w takim razie powinny też zostać przedstawione w możliwie obiektywny sposób.
Oczywiście można tu jeszcze dyskutować nad samymi liczbami i historią, która jest za nimi ukryta – skupiam się na samym wykresie. Poniżej „uczciwe” proporcje.
Wykres 4
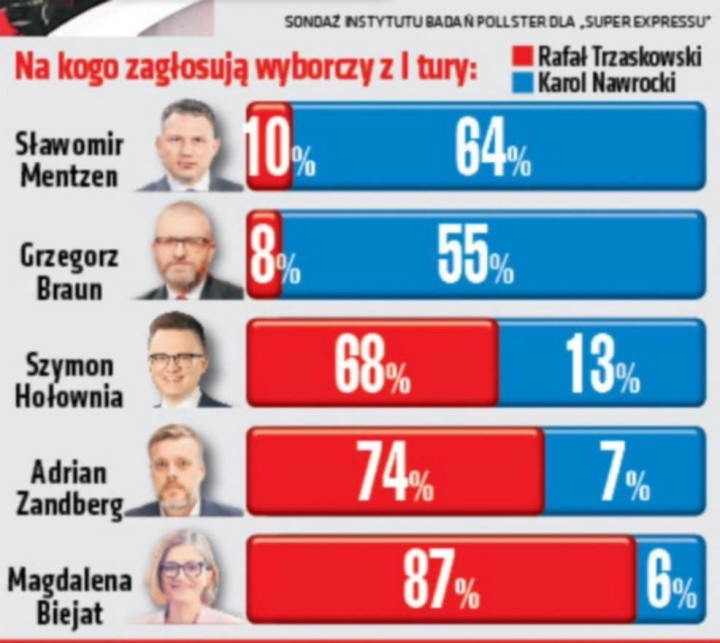
Ten wykres na pierwszy rzut oka jest zły, bo sumy procentów są dla każdego kandydata inne. Jak zaraz zobaczymy, wcale nie jest zły – ale fatalny.
Jak można się domyślić, brakuje tu trzeciej opcji: „nie wiem”, „nie zagłosuję” itp. Są różne podejścia, jak uwzględnić taką kategorię w tego typu sondażach, najbezpieczniej jest po prostu umieścić ją na wykresie. Czasem uzasadnione jest pominięcie jej i przeskalowanie procentów tak, by 100% oznaczało tylko zdecydowanych. Tutaj jednak autorzy założyli, że wszyscy niezdecydowani zagłosują na… Karola Nawrockiego. Spójrzmy na poniższy wykres, w którym uwzględniłem dodatkową kategorię (wiadomo z brakujących procentów, jak duża powinna być).
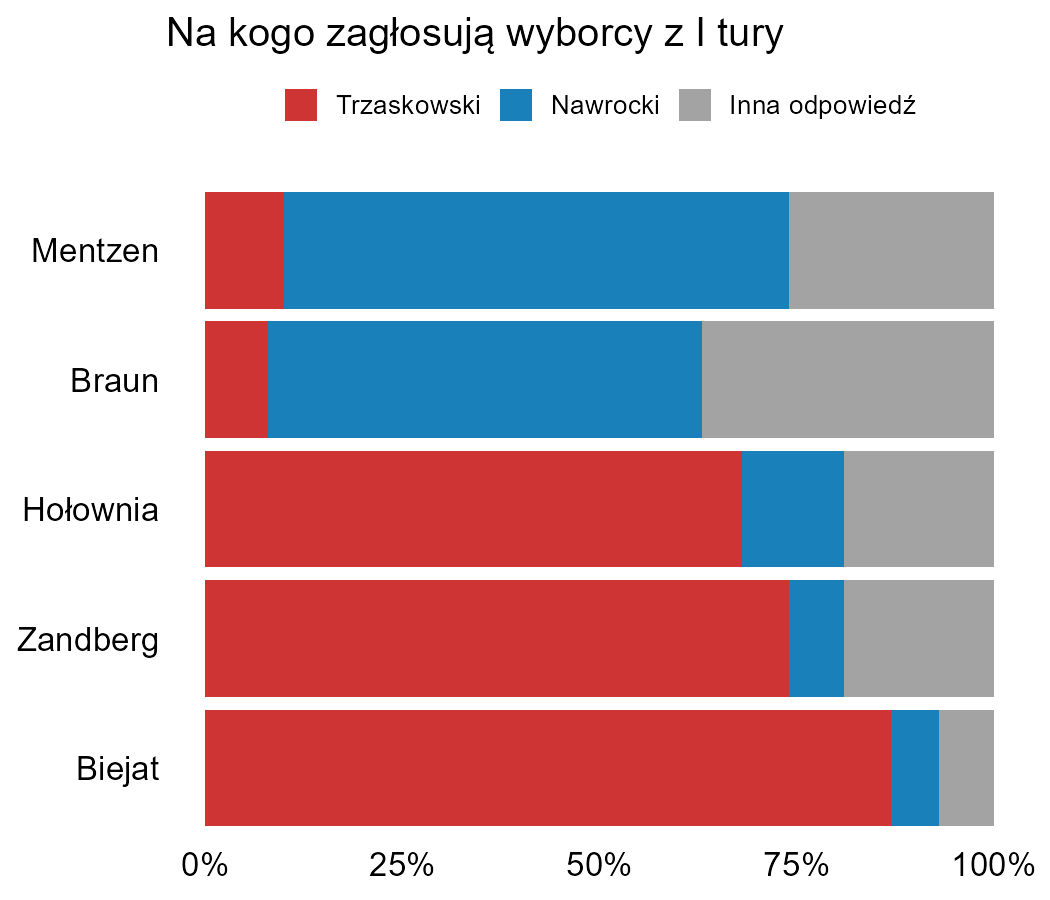
Jeśli teraz pomalujemy szare paski na niebiesko, to proporcje będą się mniej więcej zgadzać. „Mniej więcej”, bo w przypadku Szymona Hołowni nawet dorzucenie szarego paska nie wystarczyło (na wykresie Super Expressu niebieski jest jeszcze dłuższy).
Wykres 5
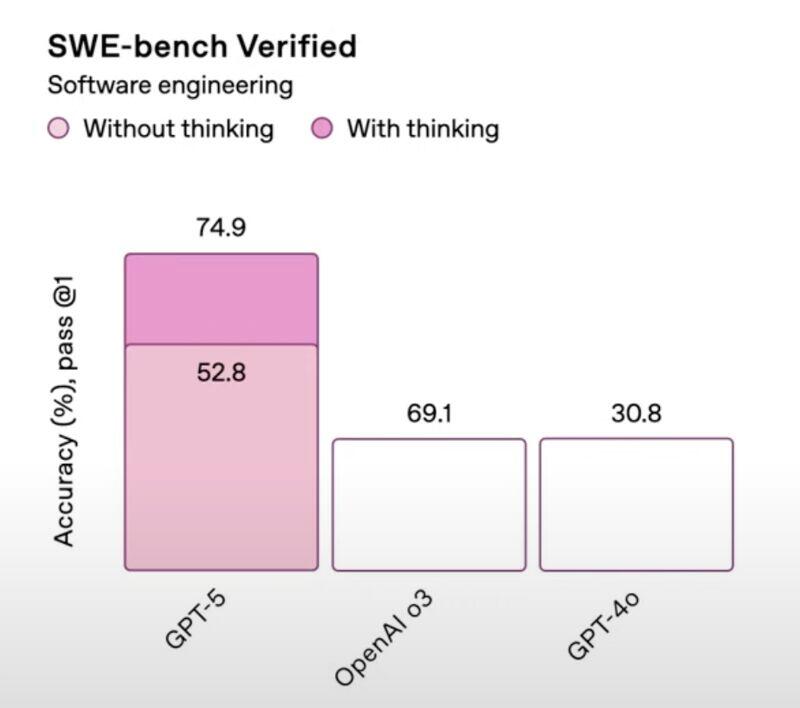
W przypadku tego popularnego wykresu z prezentacji ChatGPT mamy ewidentny problem z długością drugiego słupka. A może to słupek jest w porządku, ale podana wartość nieprawidłowa? W zasadzie, czy mamy jakąś gwarancję, że dane z pozostałych słupków są poprawne?
Na oficjalnej stronie OpenAI opublikowano poprawiony wykres z dłuższym drugim słupkiem:
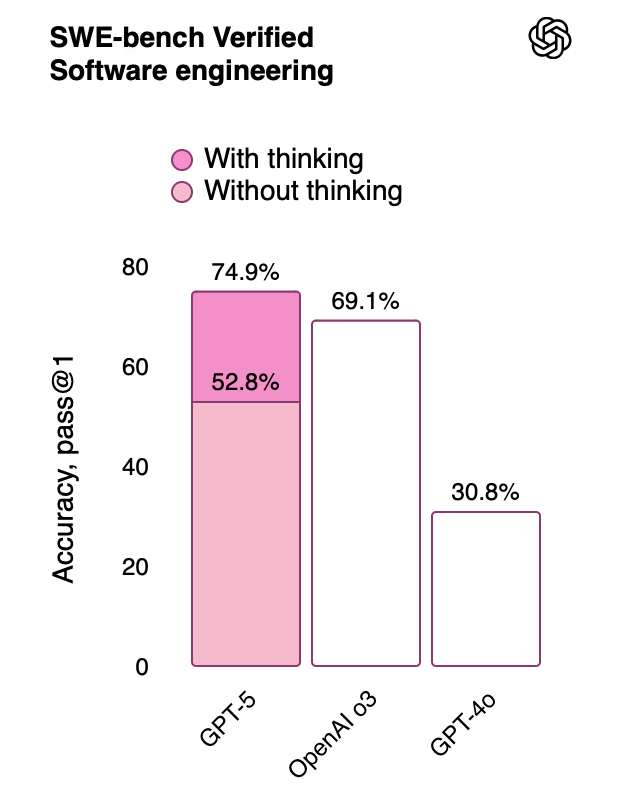
Oczywiście tego typu pomyłki mogą się zdarzyć, czy w takim razie warto ten przypadek w ogóle omawiać? Zdecydowanie! Po pierwsze, nie mówimy tu o jakiejś wewnętrznej prezentacji dla zarządu, ale o dużym wydarzeniu, które śledziło sporo osób. Po drugie, z dużym prawdopodobieństwem omawiany wykres został stworzony przez prezentowany (reklamowany!) model ChatGPT5 (without thinking?). Gdyby był robiony przy pomocy jakiegoś narzędzia do tworzenia wykresów, raczej ciężko o taki błąd.
Wykres 6
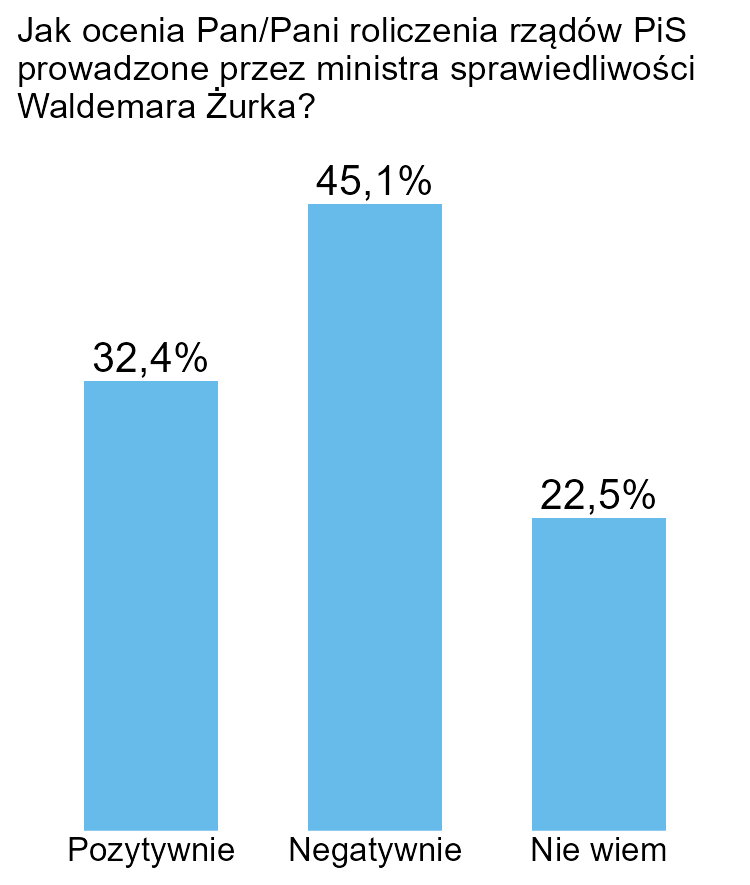
Z wykresu wyraźnie wynika, że poprawną odpowiedź na to pytanie podało 45,1%…
Kolory zielony i czerwony nie są neutralne. Zielony zwykle łączony jest z czymś pozytywnym, czerwony negatywnym, więc odwrócenie tego powiązania wprowadza w błąd. Oczywiście domyślamy się, dlaczego stało się tak akurat w przypadku tego wykresu.
Jak go poprawić? Odwrócenie kolorów niekoniecznie jest dobrym pomysłem, bo rzeczywiście dla części osób odpowiedź „Negatywnie” może być odbierana pozytywnie. W takich przypadkach najlepiej zastosować neutralną kolorystykę. Można też zrezygnować z wykresu kołowego na rzecz słupkowego, wtedy kolor w ogóle nie jest potrzebny.
Wykres 7
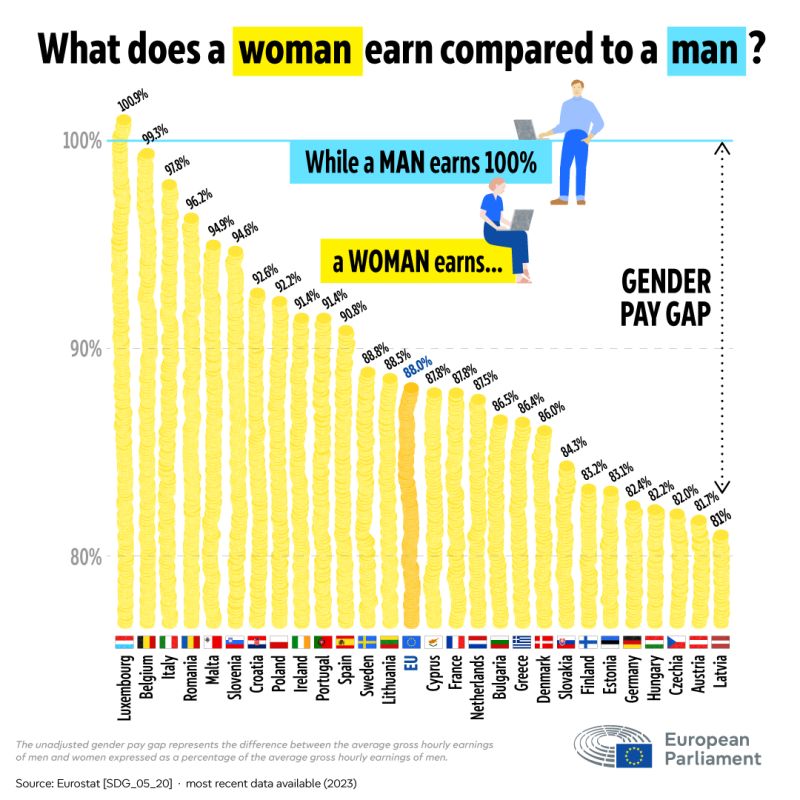
Klasyczny przykład, w którym oś Y zaczyna się nie tam, gdzie powinna – czyli w zerze. Mimo że są sytuacje, w których jest to dobre rozwiązanie, a przynajmniej można znaleźć jakieś argumenty za nim, to tutaj występują co najmniej dwa problemy. Po pierwsze, wykres słupkowy praktycznie zawsze powinien zaczynać się w zerze. Co do zasady, służy on pokazywaniu zliczeń (lub procentów). Ma to sens, bo jeśli czegoś jest 10, to jest też 9, 8 itd., aż do zera (gdy prezentujemy średnie, tego sensu jest mniej). I gdy widzę wykres słupkowy, oczekuję, że będzie zaczynał się w zerze – i na tej podstawie interpretuję pokazane różnice. W przypadku wykresu punktowego lub liniowego tego oczekiwania nie ma, bo jest znacznie więcej sytuacji (danych), gdy zero nie jest dobrą referencją.
Drugi problem z tym wykresem jest taki, że pokazuje lukę płacową przy pomocy strzałki. Jak się ma jej wielkość do słupka dla Łotwy? Jest kilka razy dłuższa, co nie ma sensu.
Szczerze mówiąc, gdyby nie ten drugi problem, to mnie osobiście aż tak nie raziłoby, że oś Y nie zaczyna się od zera. Różnicę na poziomie 10 p.p. między państwami możemy tu traktować jako na tyle dużą, że wartą wyraźnego przedstawienia. Zaraz zobaczymy, co z tym zrobić, póki co pokażmy słupki w pełnej długości.
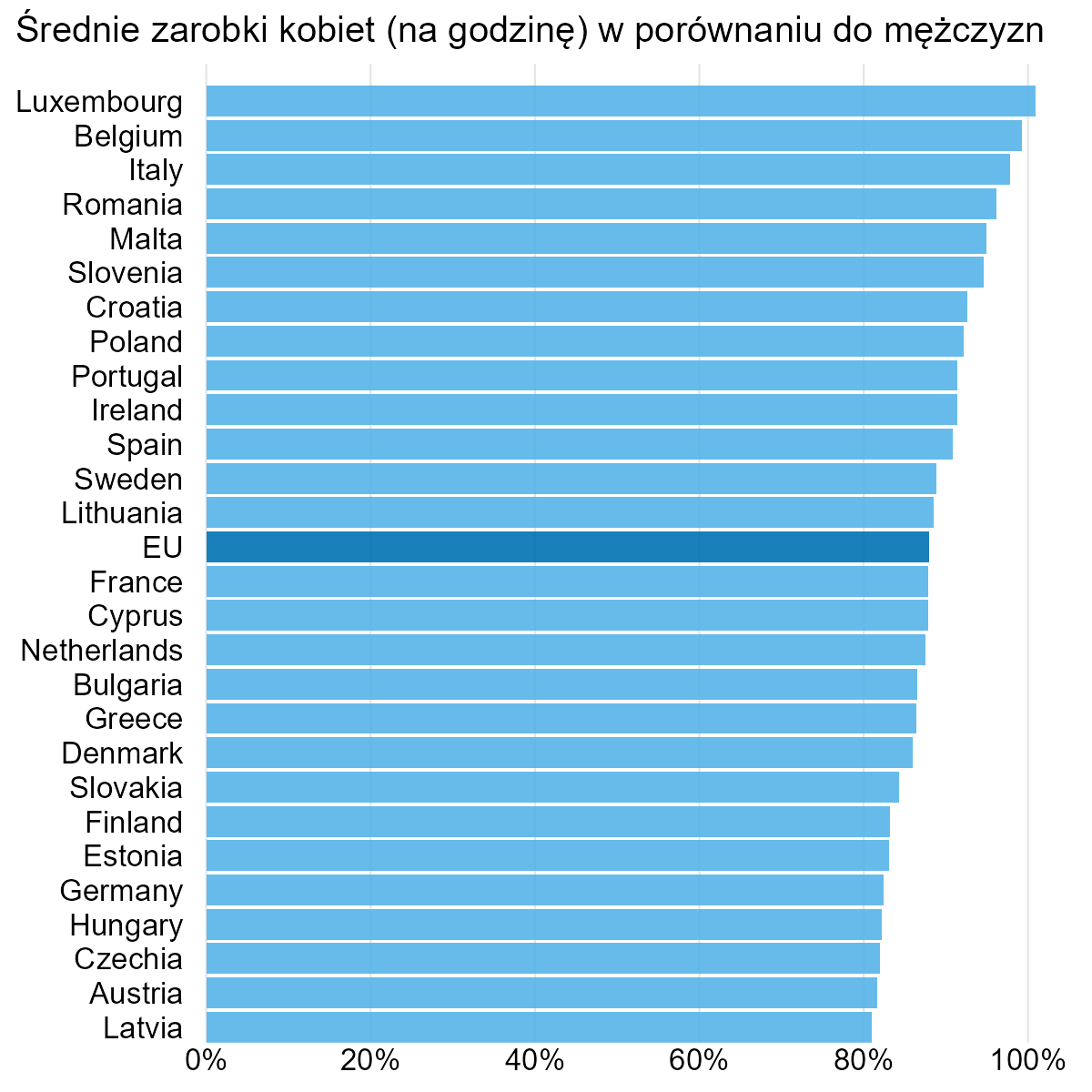
W tytule dodałem informację, że dane tyczą się zarobków godzinowych oraz że mówimy o ŚREDNIEJ różnicy w płacach. W oryginale brakuje tego słowa i grafika sugeruje, jakby każda kobieta zarabiała mniej od mężczyzny. Ewentualnie że te niższe zarobki wynikają z samego faktu „bycia kobietą”, co też nie jest prawdą, bo wykres przedstawia nieskorygowaną lukę płacową (innymi słowy: jedynie korelację). Oprócz tego wydaje mi się, że wygląd oryginalnych słupków nie oddaje powagi tematu. Rozumiem, że to miały być monety, ale mnie kojarzą się z chrupkami kukurydzianymi.
A co zrobić, jeśli chcemy bardziej skupić uwagę odbiorcy na różnicach między krajami? Moim zdaniem najlepiej przedstawić samą lukę płacową, jak niżej.
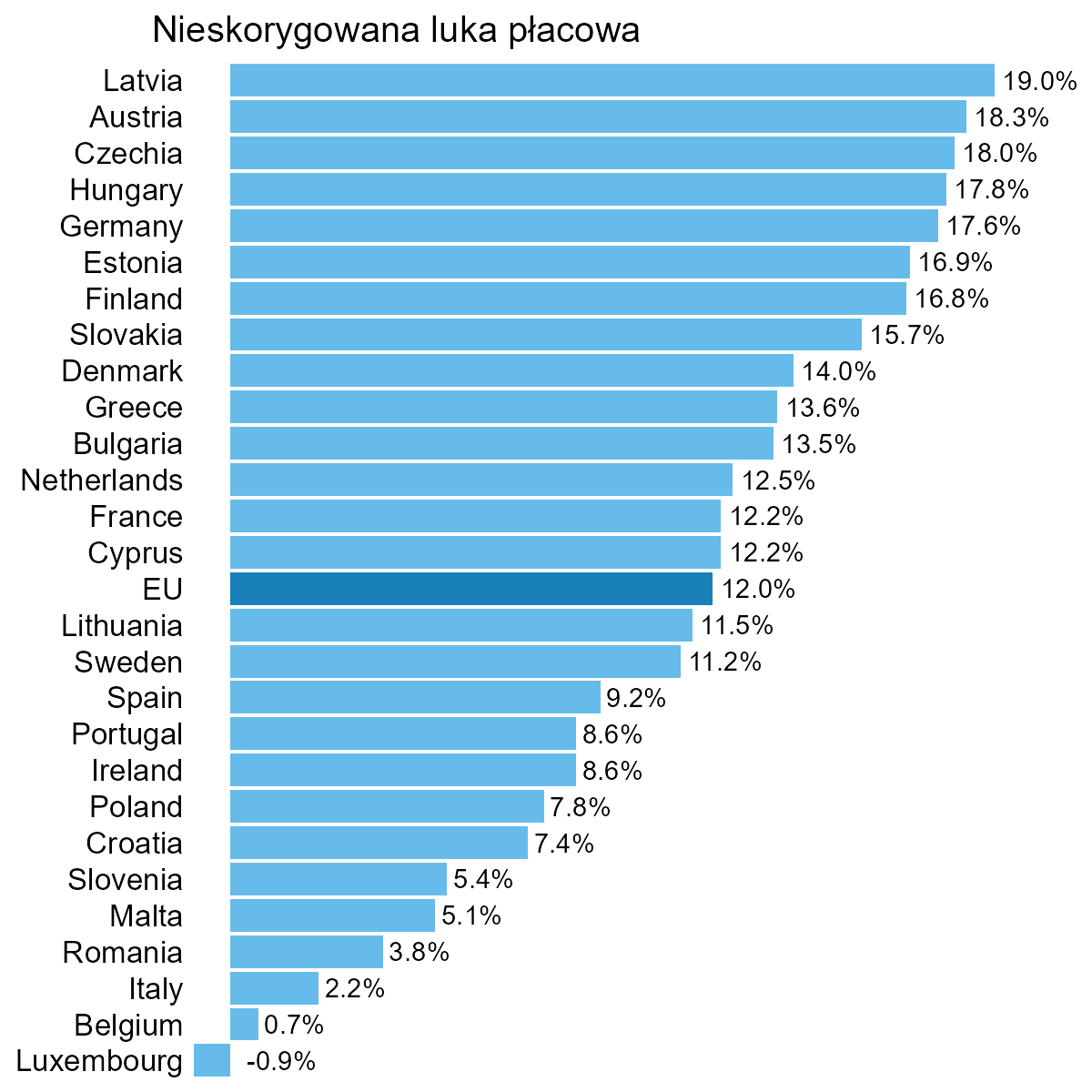
Oczywiście jeśli taki wykres miałby zostać gdzieś opublikowany, wymaga podania dodatkowych informacji, sam tytuł nie wystarczy.
Wykres 8
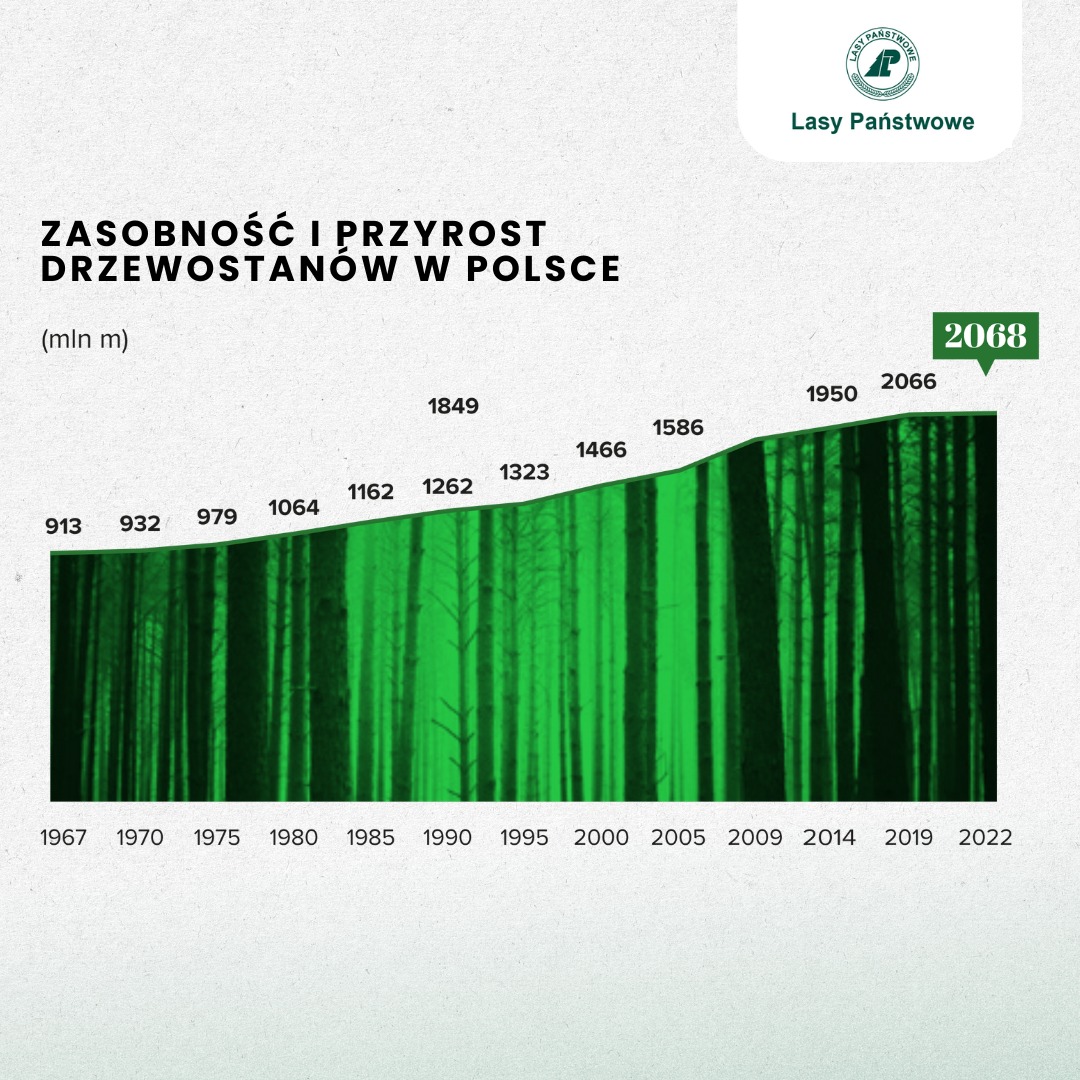
Gdy oś Y nie zaczyna się w zerze, prawie zawsze znajduje się gdzieś powyżej, jak w poprzednim przypadku. Dlatego to interesujące zobaczyć wykres, w którym początek osi Y to liczba ujemna! Na oko jest to mniej więcej -1200:
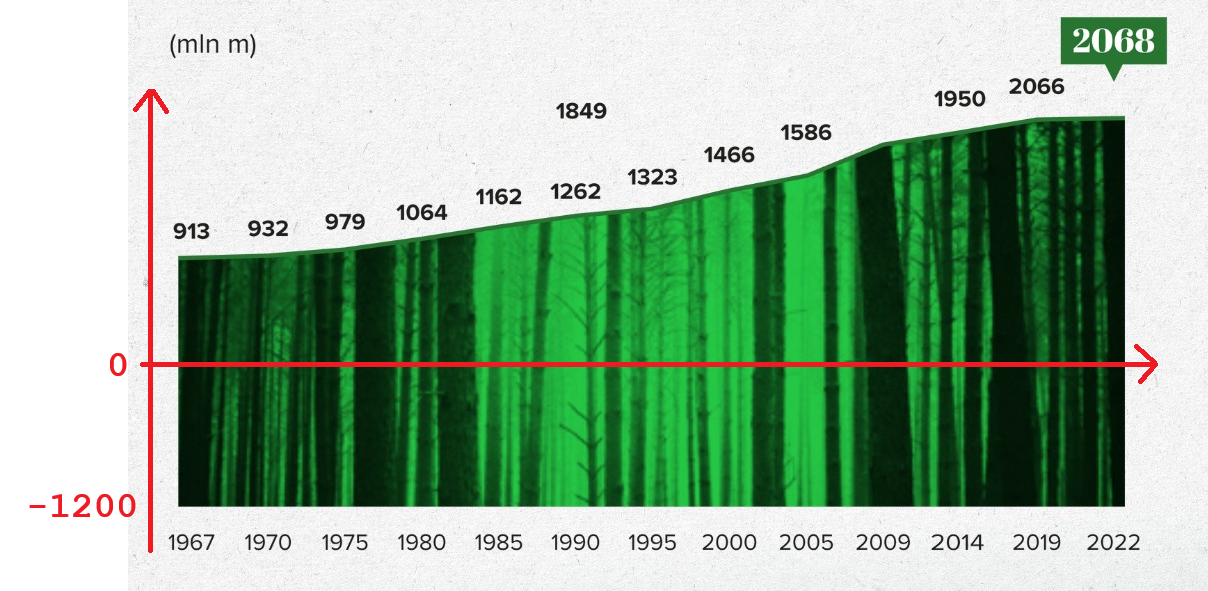
Skutkiem jest „spłaszczenie” różnic, to znaczy wydają się mniejsze, niż gdyby oś Y zaczynała się w zerze. Poniżej poprawiona wersja.
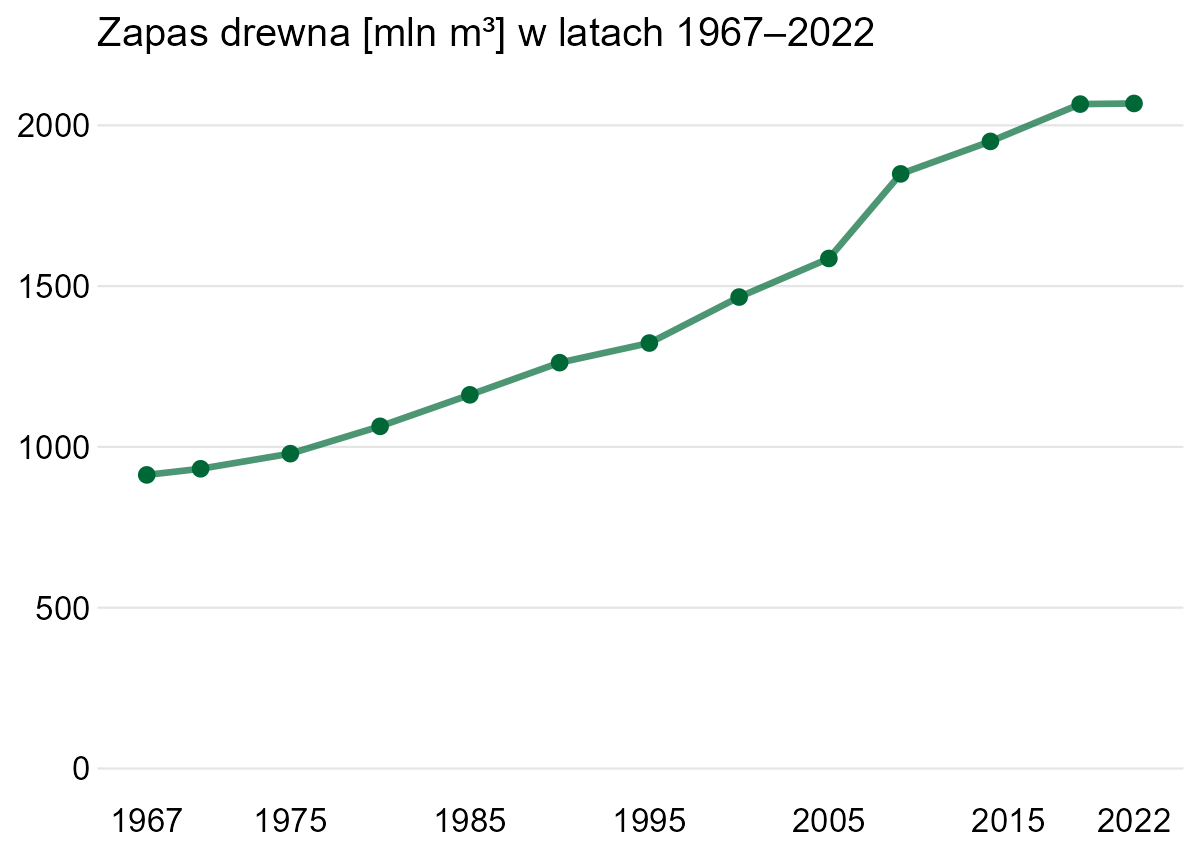
Poprawiłem też oś X, bo nie jest w równych odstępach, mimo że to sugeruje pierwotny wykres (pierwszy i ostatni przedział są trzyletnie). Oprócz tego zasobność drzewostanu to objętość drewna na danym obszarze i jednostką jest metr sześcienny na hektar. Na wykresie podano zapas drewna.
Warto dodać, że na wykresach liniowych, w przeciwieństwie do słupkowych, oś Y nie musi zaczynać się w zerze – choć wciąż to dobra domyślna opcja. Gdy jest to uzasadnione, początek układu współrzędnych może być w innym miejscu (https://danetyka.com/wykres-od-zera/). W oryginalnej wersji mieliśmy tu jednak wykres powierzchniowy (warstwowy) i wtedy niezaczynanie od zera trudno obronić. Oko ludzkie ocenia pole powierzchni i nie powinniśmy manipulować jego wielkością.
A co z tłem? Cóż, nie przepadam za takim upiększaniem wykresów, a tutaj dodatkowo można odnieść wrażenie, że pnie drzew przekazują dodatkową informację. Natomiast wykres staje się przez to bardziej atrakcyjny i w konkretnych przypadkach może być to przeważający argument.
Wykres 9
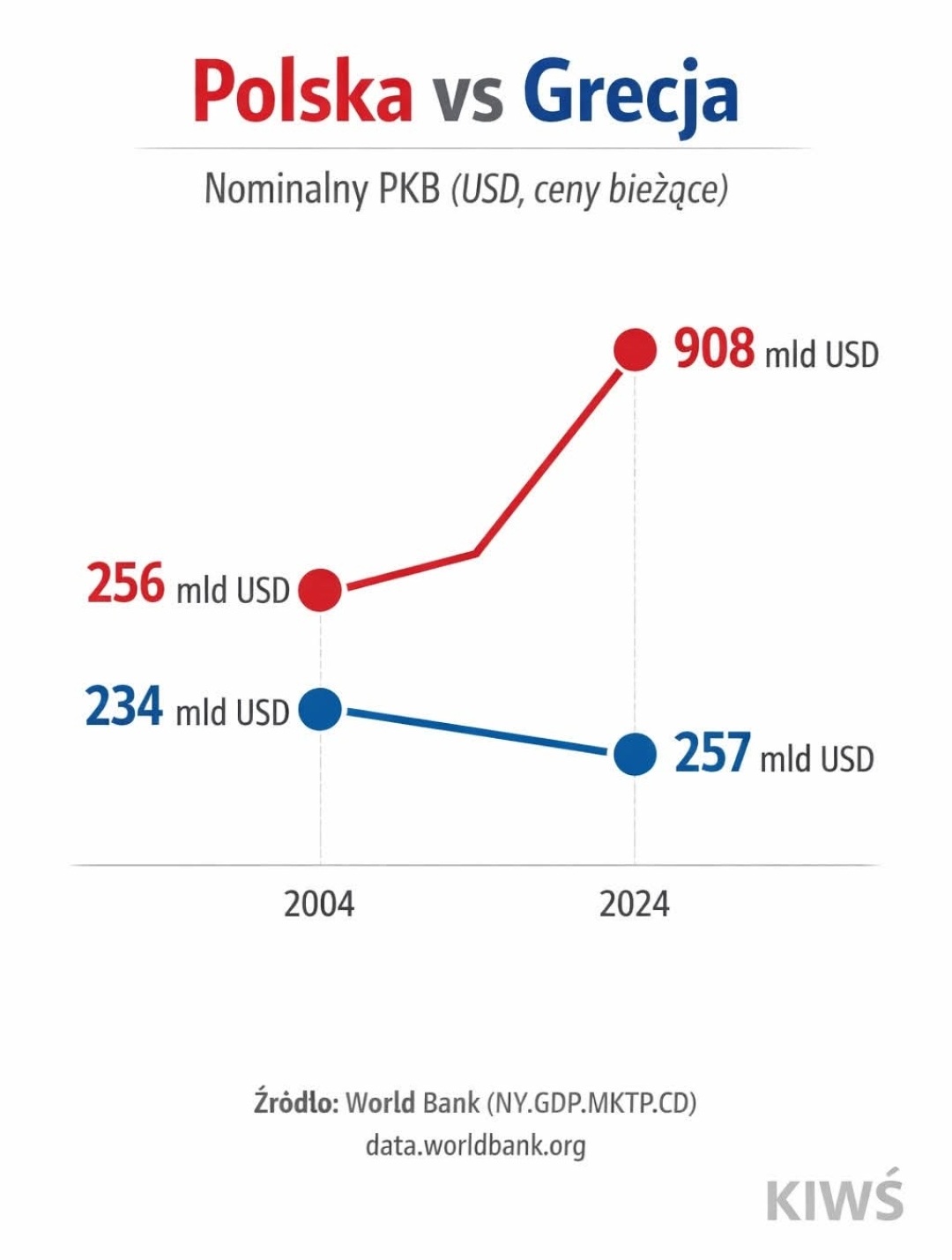
Tym razem PKB Polski tak bardzo wzrosło, że aż zaburzyło kolejność liczb naturalnych i 257 jest mniejsze od 234. To niestety jeden z wielu przykładów wykresów generowanych przez modele językowe (można to rozpoznać choćby po słowie „bieżące”). Poniżej kolejny.
Oczywiście fakt, że modele mają takie problemy, nie jest niczym dziwnym. Ciężko jednak zrozumieć, że ktoś publikuje takie obrazki. Przyznam też, że nie byłem przekonany, czy jest na nie miejsce w plebiscycie, bo można by z nich zrobić osobny konkurs. Istnieją całe strony z takim dziadostwem, których nie chcę linkować. Ostatecznie stwierdziłem, żeby potraktować je zbiorczo, a wykres z PKB Grecji i Polski niech będzie ich reprezentantem.
Wykres 10
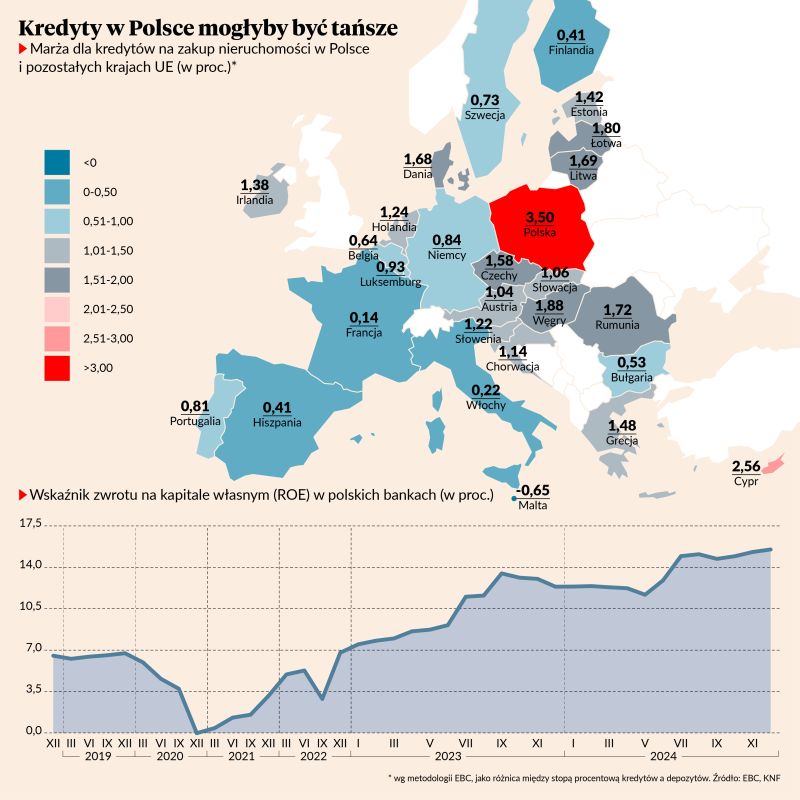
Grafikę pokazuję w całości, natomiast chciałem zwrócić uwagę głównie na dolny wykres. Choć do mapy też można mieć zastrzeżenia: kolory są tak dobrane, że różnica między Polską a pozostałymi krajami wydaje się zbyt dobitnie pokazana. Gradient z dwoma tak różniącymi się kolorami najlepiej stosować wtedy, gdy da się obiektywnie wskazać jakiś „poziom zero”. Wtedy wartości powyżej można pokolorować jednym kolorem, a poniżej drugim (np. temperatura powietrza).
Problem z dolnym wykresem jest taki, że ostatnie dwa lata zajmują więcej miejsca niż pierwsze cztery. Mimo że wartości ROE były stosunkowo niskie przez większość okresu 2019-2024, to wrażenie jest inne. W szczególności ROE powyżej 7% to prawie 60% długości wykresu, gdy w rzeczywistości takie wartości były przez 33% całego pokazanego czasu.
Autorzy tłumaczyli ten zabieg w taki sposób, że wcześniejsze dane były podawane kwartalnie, a dopiero od 2023 są miesięczne. To oczywiście nie jest dobry argument, odpowiednie przedstawienie takich danych nie sprawia żadnych trudności:
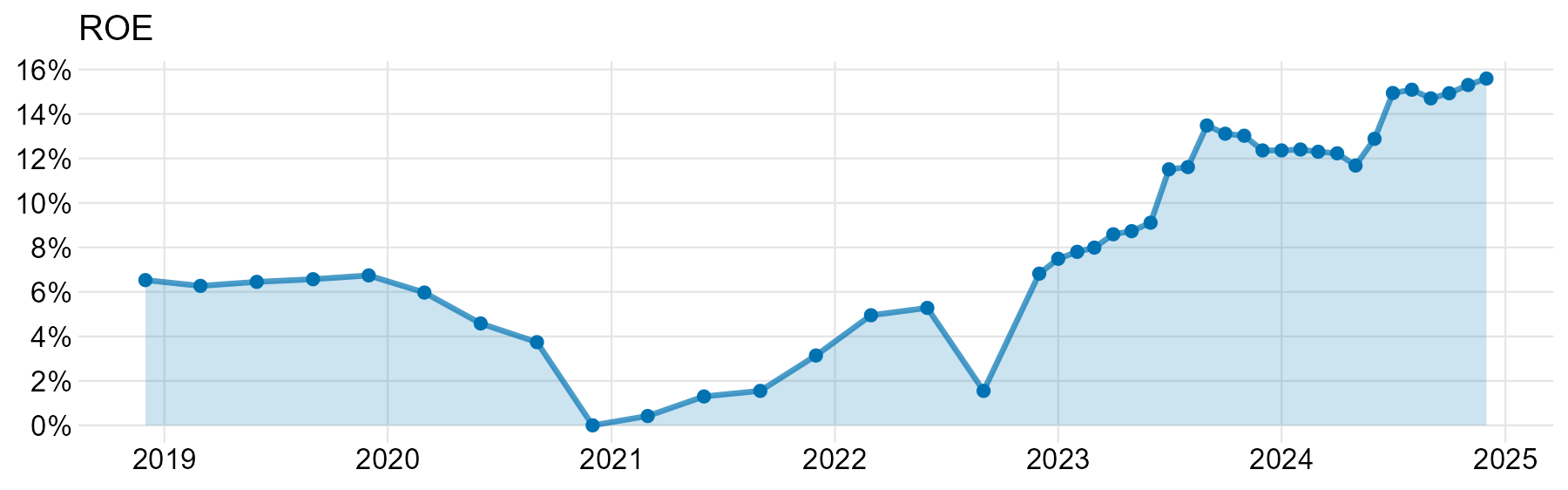
Jak widać, punkty dla wcześniejszych lat są rzadsze, bo odległość między nimi to trzy miesiące, a nie miesiąc.
Wykres 11
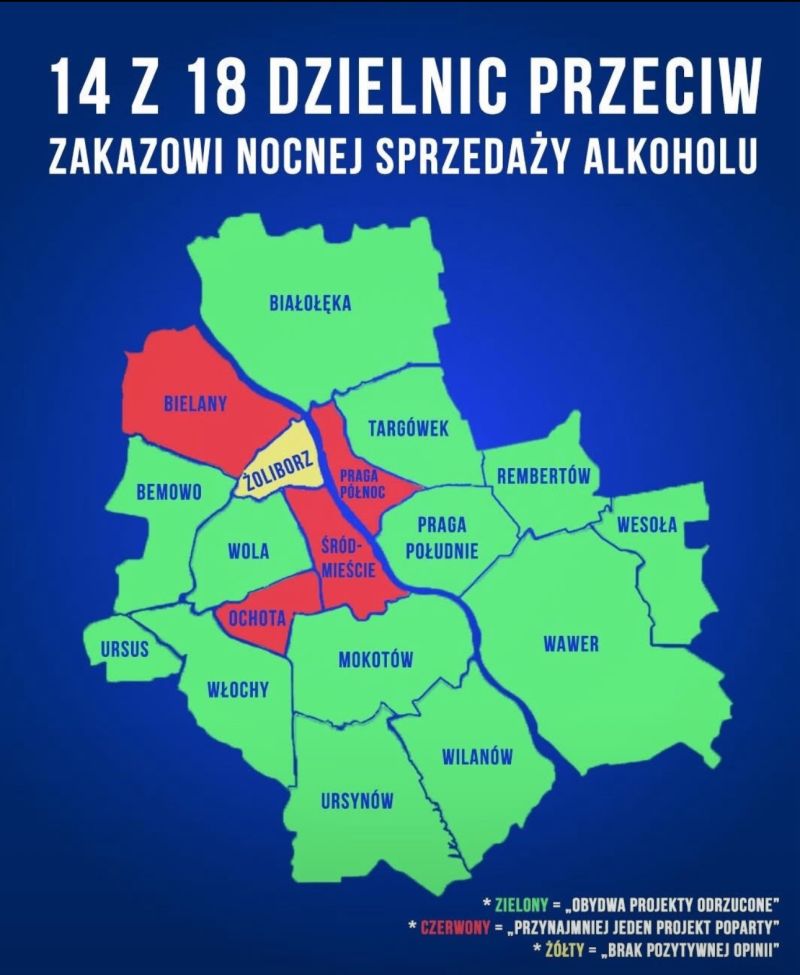
Kolejny przykład z interesującą kolorystyką. Mamy dobre i złe dzielnice Warszawy, gdzie dobre to te, które zagłosowały przeciw nocnej sprzedaży alkoholu.
Ale co tu zrobić, odwrócić kolory? Wtedy czerwony będzie oznaczał „przeciw”, co wydaje się mieć sens. Problem w tym, że jest to „przeciw zakazowi”. To może nie odwracajmy kolorów, ale tytuł: dzielnice, które głosowały za sprzedażą alkoholu. Ale po pierwsze, one niekoniecznie głosowały „za sprzedażą”, tylko przeciw konkretnym projektom. Po drugie, nawet jeśli traktować to jako głos „za”, to wydaje się, że takie kolory po prostu nie są tutaj najlepszym pomysłem.
A tak swoją drogą, to w jaki sposób te dzielnice głosowały? Wykonano badanie opinii publicznej i większość mieszkańców z danej dzielnicy była za lub przeciw? Z komentarzy pod wykresem wynikało, że wiele osób tak tę grafikę zinterpretowało. W rzeczywistości głosowali radni dzielnic nad dwoma projektami zakazu sprzedaży (różniły się głównie godzinami obowiązywania zakazu). Kolorem czerwonym oznaczono dzielnice, w których ponad połowa radnych zagłosowała za co najmniej jednym z projektów. Wydaje się, że jest to ważna informacja, którą warto dodać do wykresu.
Poniżej dwie propozycje poprawy, które wykonała Klaudia Stano. Użyto symboli X i V do oznaczenia, czy dzielnica była za czy przeciw projektom. Na oryginalnej grafice Żoliborz jest oznaczony żółtym kolorem, ale z informacji, które udało się znaleźć, wynika, że radni z tej dzielnicy ostatecznie nie poparli żadnego projektu, więc użyto symbolu X.
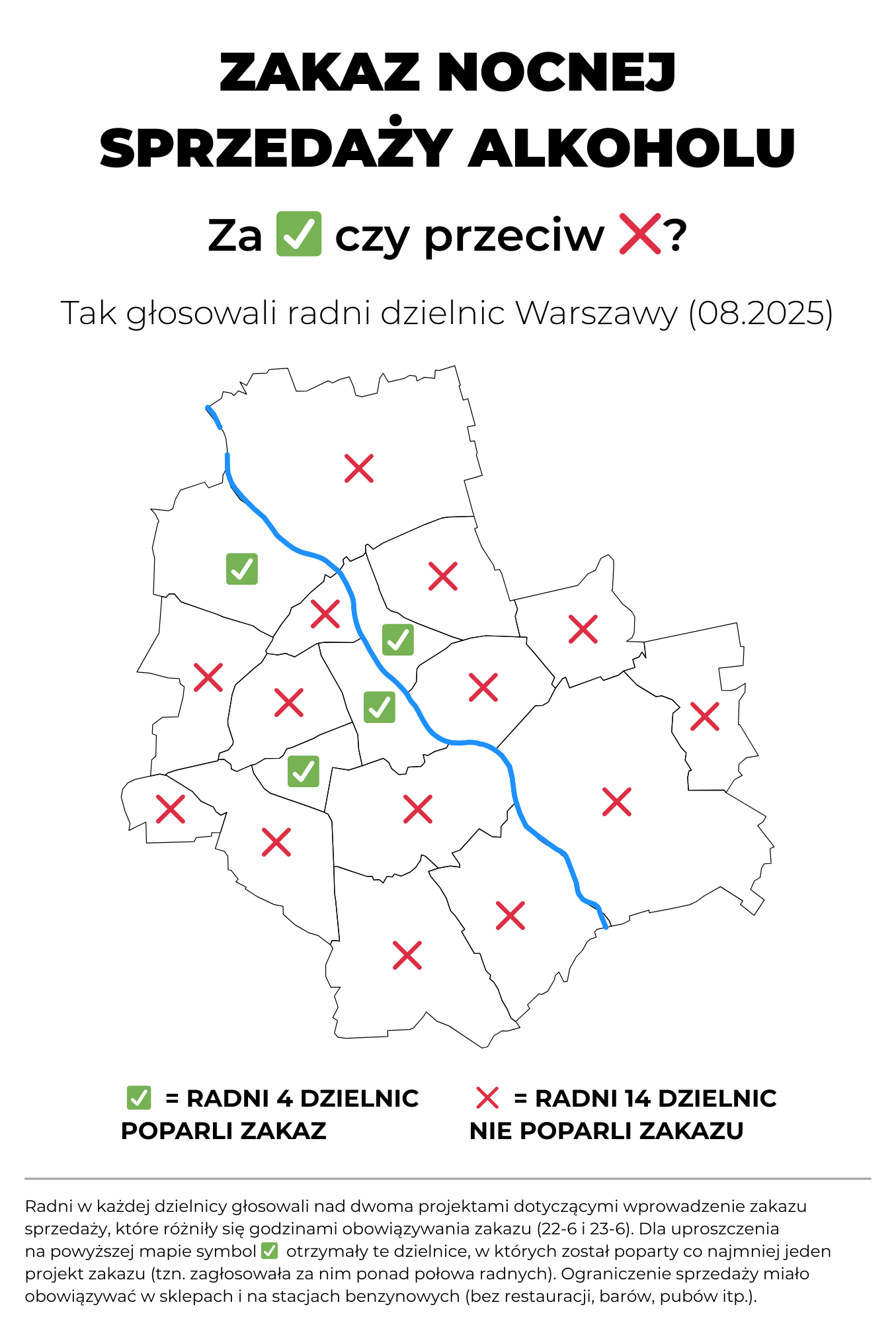
W powyższej wersji wciąż występuje problem z podwójnym zaprzeczeniem (głosowanie przeciw zakazowi) i X można interpretować nie jako „przeciw”, ale jako oznaczenie zakazu. Oprócz tego mamy kolory, co do których można mieć wątpliwości (choć teraz wyraźniej widać, że tyczą się jedynie bycia za lub przeciw; i niestety bez nich grafika jest znacznie mniej czytelna). Dlatego w drugiej propozycji symbole odnoszą się do treści głosowanych projektów.
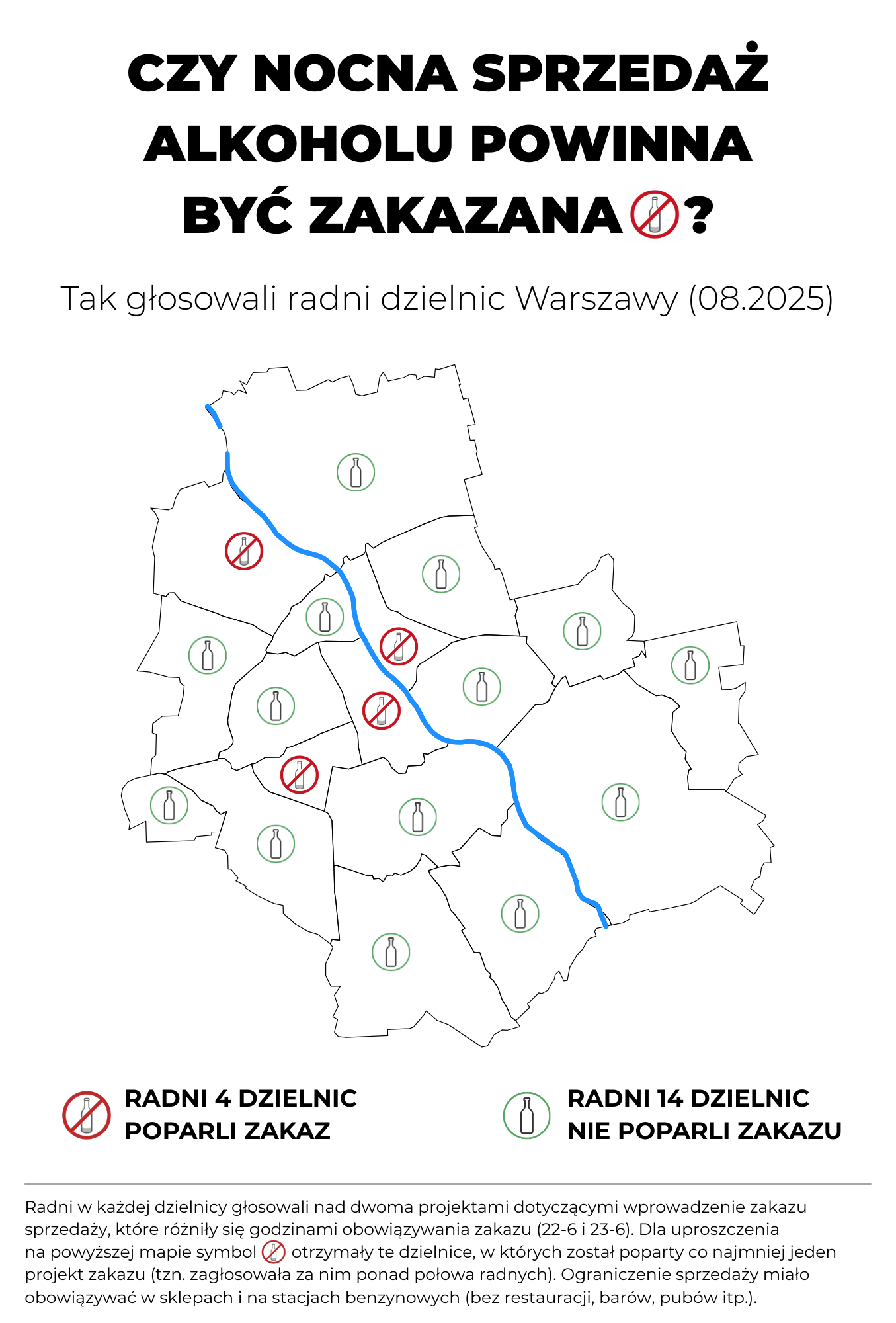
Wykres 12
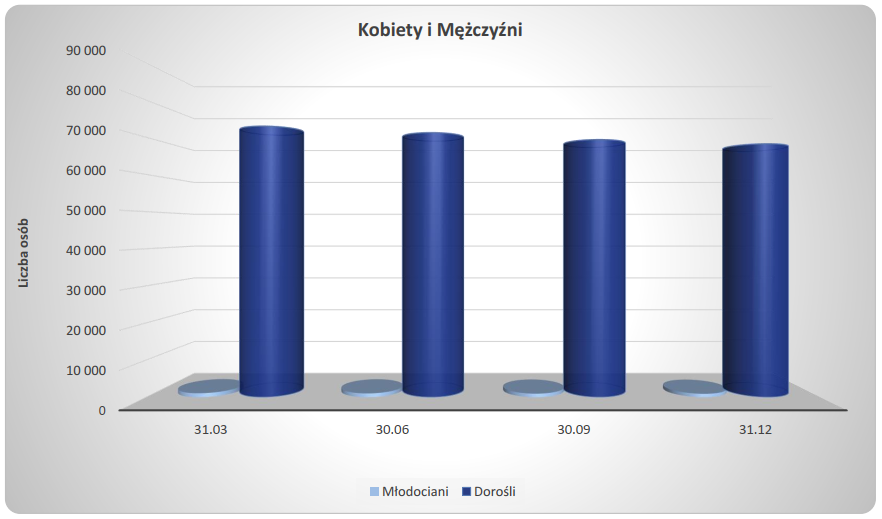
Klasyczne kloce w formie walców, nie mogło czegoś takiego zabraknąć. Placki również są interesujące. Wykres pojawił się w poważnym raporcie Centralnego Zarządu Służby Więziennej i przedstawia liczbę osadzonych w polskich więzieniach z podziałem na młodocianych i dorosłych.
W skrócie: takich wykresów po prostu się nie robi… Perspektywa 3D mocno zniekształca odbiór wysokości słupków. Jak myślicie, pierwszy słupek kończy się na wartości poniżej czy powyżej 75 tysięcy? Dokładnie jest to 74042. Oczywiście w wykresach nie chodzi o to, żeby takie dokładne dane być w stanie odczytać, ale tutaj wrażenie jest takie, że ta liczba jest o kilka tysięcy większa.
A kto zgadnie, jak dużo jest młodocianych osadzonych? Z pewnością znacznie mniej niż dorosłych – to wykres pokazuje dobitnie. Wydaje się, że wciąż to interesujące, czy jest ich 100, 500 czy 2000 (w rzeczywistości około 1000).
Jak ten wykres poprawić poza rezygnacją z trójwymiarowości? Moim zdaniem, najlepiej zrezygnować ze wszystkiego. Wykresy powinny być wartością dodaną, a tu nie widzę żadnej. W raporcie jest tabela z dokładnymi liczbami i to całkowicie wystarcza. To znaczy takie dane wciąż może być warto zaprezentować na wykresie, ale dodając więcej informacji, na przykład dłuższy okres. Proponowałbym też przedstawić liczbę młodocianych na niezależnym wykresie, z osobną skalą osi Y.
Przy okazji, sprawdziłem, jak te statystyki pokazano we wcześniejszych raportach i poniżej parę przykładów.

Wykres 13
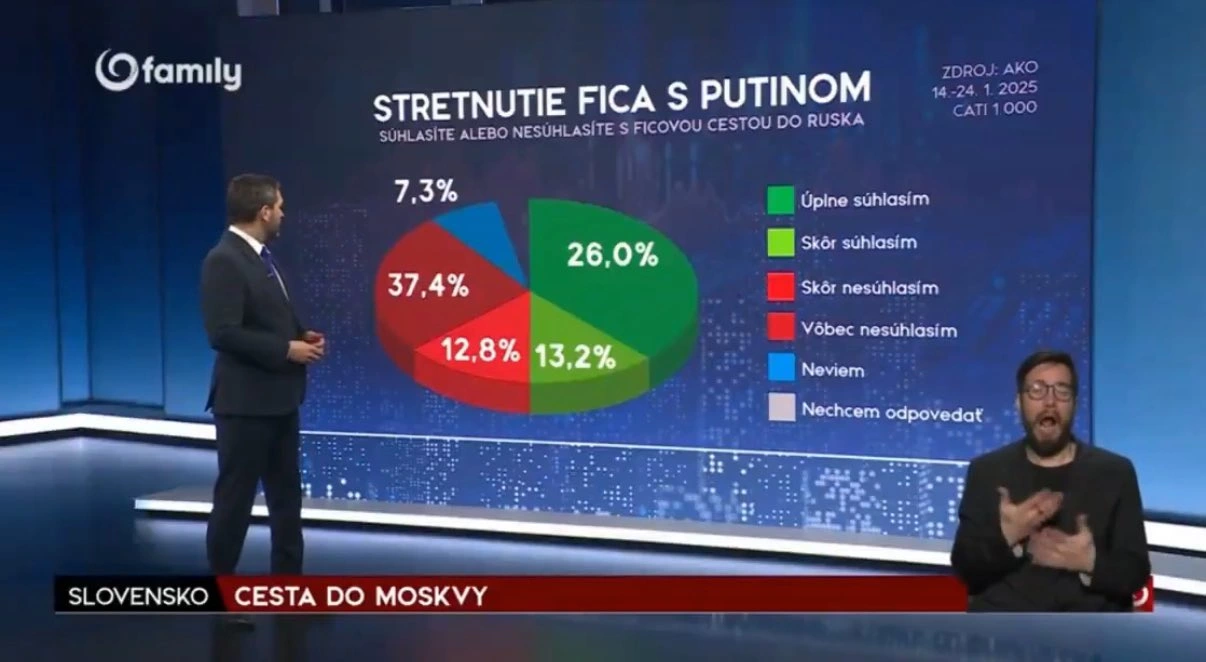
Na wykresie odpowiedzi na pytanie: „Czy zgadzasz się z podróżą Fico do Rosji?”. Jak widać, połowa Słowaków się zgadza (zielone pola), natomiast jest to tak zwana „mniejsza połowa”, bo wynosi 39,2%.
Po dłuższym zastanowieniu można dojść do wniosku, że autorzy po prostu zamienili etykiety 26% i 37,4%, ale jak się okazuje, liczby są prawidłowe.
Jak to poprawić? Cóż, po prostu narysować to dobrze. Mimo że wykres kołowy zwykle nie jest najlepszym wyborem (https://danetyka.com/wykresy-kolowe/), to w tym przypadku da się obronić (byle nie 3D). Mamy dwie główne odpowiedzi (zgadzam się lub nie zgadzam) i na takim wykresie dobrze widać, że na przykład połowa osób się nie zgadza. To znaczy byłoby widać, gdy nie ten błąd.
Wykres 14
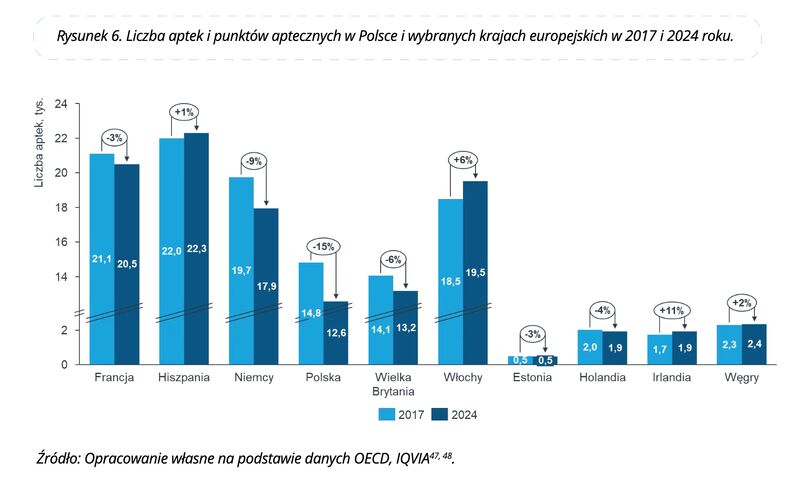
Wykresy słupkowe powinny zaczynać się od zera? To zacznijmy od zera, tylko usuńmy trochę środka! Zabieg zastosowany na tym wykresie jest niestety dość popularny, ale zdecydowanie niepolecany. Mimo że zostaliśmy ostrzeżeni, że z osią Y coś jest nie w porządku (ukośne linie), to w dalszym ciągu zupełnie zaburza to percepcję różnic. I to podwójnie: liczby aptek w pierwszych sześciu krajach wydają się mniejsze niż w rzeczywistości oraz mniejsze są różnice między latami 2024 i 2017.
Jak to zrobić inaczej? Można po prostu nie manipulować długością słupków, ewentualnie przedstawić jak niżej. Dodatkowo zaznaczyłem kolorem czerwonym kraje, w których liczba aptek spadła (o co najmniej 5%), na zielono te, w których wzrosła (o co najmniej 5%) i na czarno pozostałe.
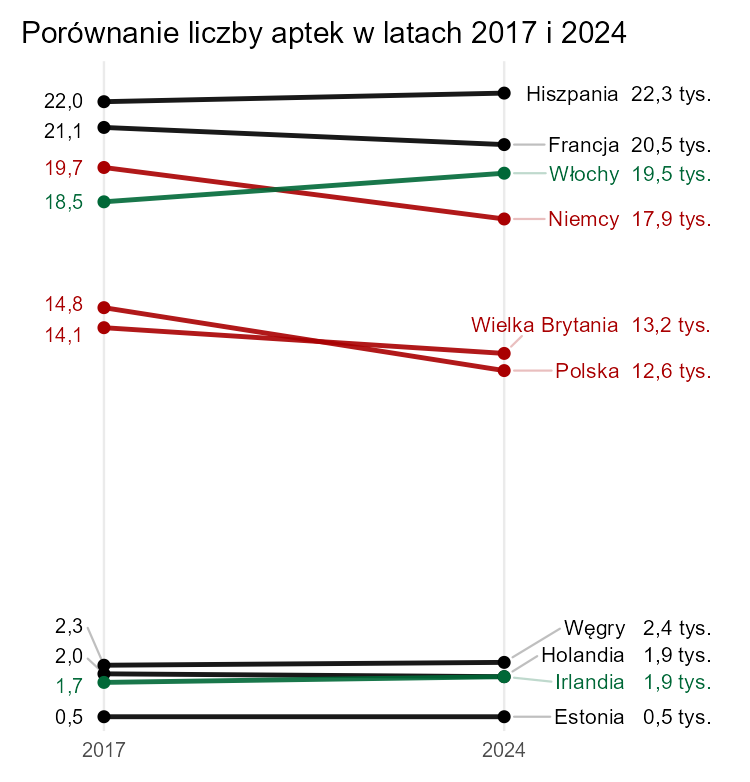
Minusem takiego rozwiązania jest pewna sugestia, że liczba aptek zmienia się liniowo między podanymi latami (choć w wersji ze słupkami wielu odbiorców i tak może w ten sposób o tym myśleć).
Ale zastanówmy się jeszcze nad liczbami, które prezentuje wykres. Nie jest żadnym zaskoczeniem, że zmiany wyrażone w bezwzględnych liczbach będą większe w większych państwach. I zapewne dlatego autorzy wykresu dodali informację o zmianie procentowej. Np. w Irlandii przybyło 11% aptek, najwięcej ze wszystkich krajów. Może w takim razie rozsądniej byłoby przedstawić te dane, odnosząc się do liczby mieszkańców? Poniżej rozkład liczby aptek na 100 tysięcy mieszkańców danego kraju.
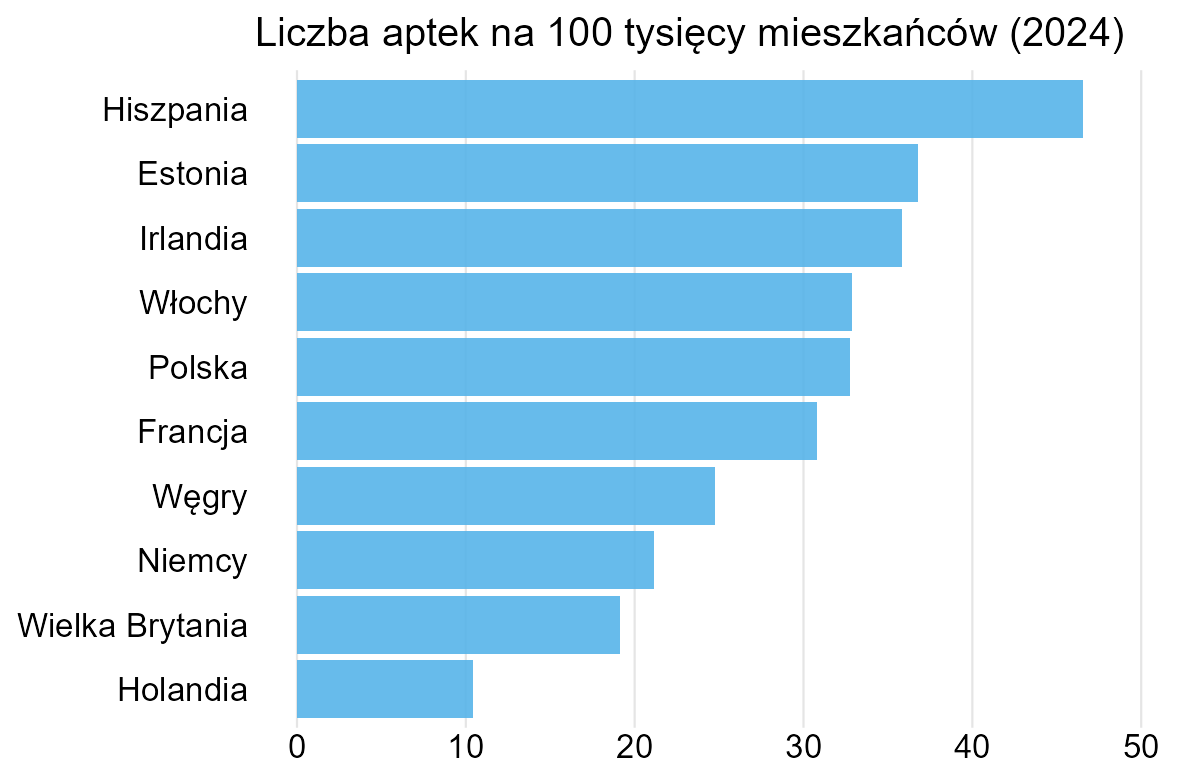
Zauważmy, że teraz znika problem, z którym próbowali sobie poradzić autorzy, to znaczy długości słupków są wystarczająco podobne, żeby nie ucinać żadnego z nich.
Wykres 15
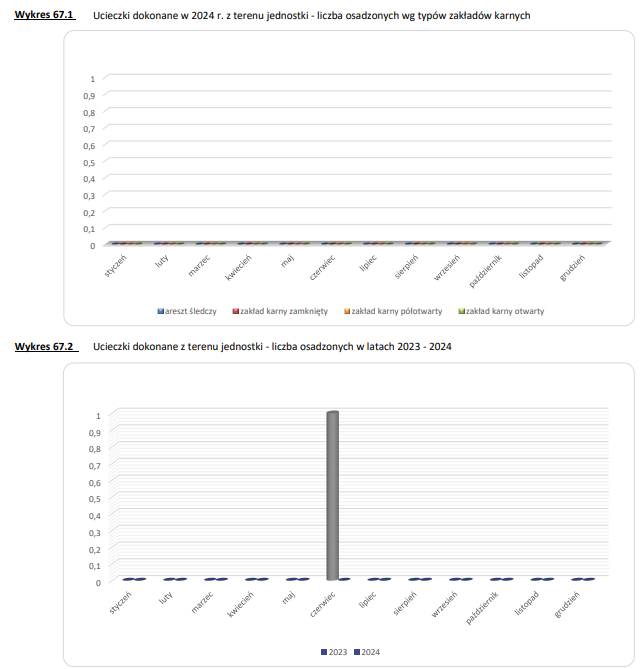
Drugi nominowany wykres z raportu Centralnego Zarządu Służby Więziennej, przedstawiający liczbę ucieczek z terenu jednostki. W zasadzie to dwa wykresy: w pierwszym mamy rozbicie na ucieczki z aresztu śledczego, zakładu karnego zamkniętego, półotwartego i otwartego, natomiast w drugim porównanie z rokiem 2023.
Cóż, jeśli chodzi o same dane, wygląda to bardzo dobrze! Sprawdziłem dołączone w raporcie tabele i rzeczywiście, całkowita liczba ucieczek w 2024 wyniosła zero. Autorzy postanowili przedstawić to na wykresie, z rozbiciem na miesiące i miejsca, z których więzień uciekł. Całe szczęście, że na pierwszym użyto formy trójwymiarowej, inaczej niczego nie byłoby widać! Zabawnie wyglądają też ułamki na osi Y, sugerujące możliwość ucieczki połowy więźnia.
Jak poprawić ten wykres? W skrócie, nie da się tego zrobić.
Wykres 16
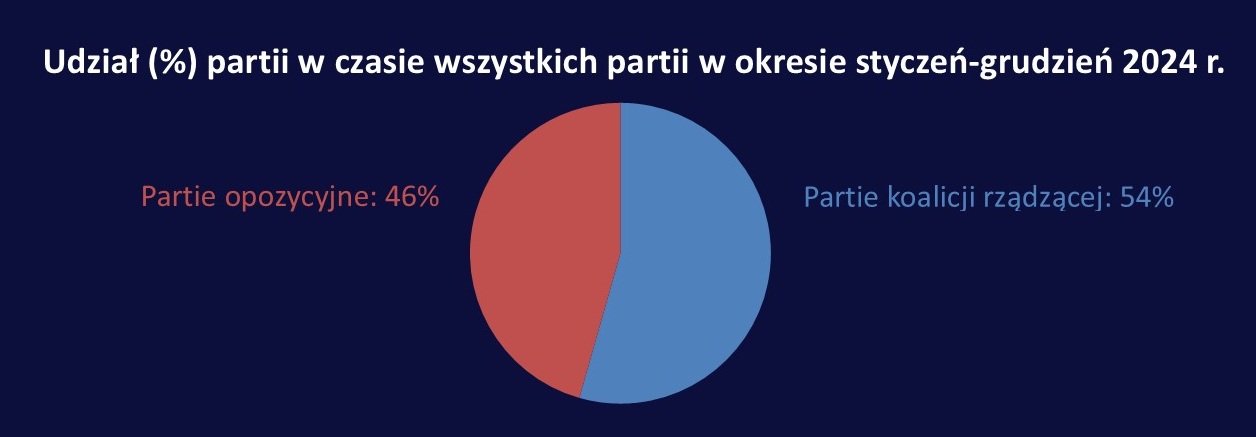
Czy da się coś popsuć na takim wykresie? Tak, można źle policzyć procenty. Wykres powstał na podstawie tych danych. Jak czytamy w podsumowaniu pod tabelą, łączny czas wszystkich partii wyniósł 743 godziny, z czego 623,5 dla koalicji rządzącej, a 119,5 dla opozycji. Niestety, autorzy wykresu zamiast podzielić 623,5 przez 743, zestawili ze sobą te dwie liczby, tzn. 54% odpowiada wartości 743, a 46% to 623,5, co oczywiście nie ma sensu.
Zgłosiłem to do KRRiT i po miesiącu wykres został poprawiony:
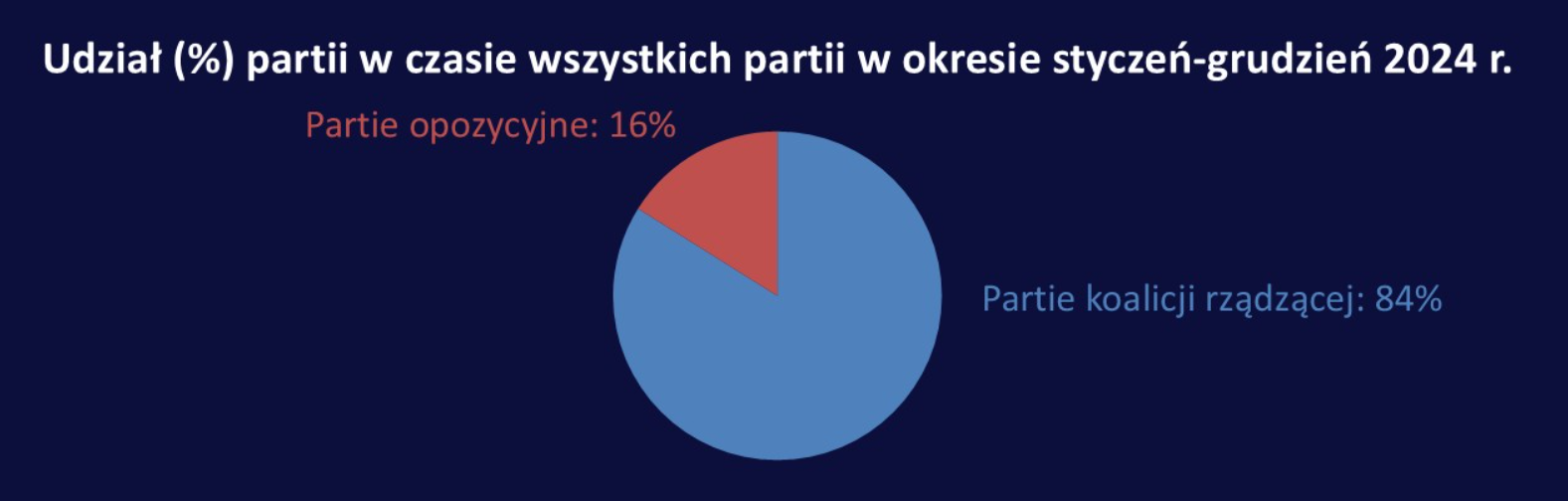
Różnica jest diametralna. Najprawdopodobniej to był tylko głupi błąd, bo dane w tabelach i opisach były poprawne. Problem w tym, że wykresy mają znacznie większe oddziaływanie („zasięgi”) niż tabelki. I media tak właśnie skomentowały te dane, tzn. spojrzały jedynie na wykres:
- „W Telewizji Polskiej S.A. w likwidacji rządzący koalicjanci też mieli przewagę, ale już nie tak znaczną. W TVP rządzący wykorzystali 54 procent czasu antenowego a 46 procent miała opozycja” (biznesalert.pl).
- „Dane TVP za okres od stycznia do grudnia 2024 r. pokazują, że w jej programach na partie koalicji rządzącej przypadło 54 procent czasu antenowego, na partie opozycyjne — 46 procent” (wirtualnemedia.pl)
Dobry przykład, jaką siłę oddziaływania mają wykresy!


