[Aktualizacja 6/2025. Artykuł opublikowałem rok temu, opierając się na wynikach wyborów do europarlamentu. W obecnej wersji analizuję wyniki drugiej tury wyborów prezydenckich, bo są bardziej “na czasie”].
W Polsce popularne jest przedstawianie wyników wyborów w formie mapek, pokazujących rzekomo dwie Polski, wschodnią i zachodnią. W zależności od poglądów, na wschodzie/zachodzie żyją ludzie roztropni, głosujący na dobrą partię X, a na zachodzie/wschodzie nieroztropni, głosujący na złą partię Y.
Nierzadko takie mapy są maksymalnie uproszczone, np. przy użyciu jedynie dwóch kolorów pokazuje się, że w danym województwie, powiecie lub gminie wygrała partia X lub Y — nie biorąc pod uwagę, że różnice mogły być niewielkie. Poza tym, nawet jeśli korzysta się z gradientu kolorów, to pomija się podstawowe różnice w strukturze wieku, płci czy miejsca zamieszkania (np. na wschodzie więcej osób mieszka na wsiach), które wiadomo, że silnie korelują z preferencjami wyborczymi.
Nie twierdząc, że nie ma żadnych powodów do podziału na wschód i zachód, przedstawię te mapki w inny sposób, uwzględniając wymienione wyżej czynniki. Będę bazował na wynikach wyborów prezydenckich z 2025 roku (druga tura) z rozbiciem na gminy.
Mapy
Zacznijmy od mapy z procentem głosów oddanych na Nawrockiego i Trzaskowskiego, przedstawionym jako gradient kolorów.

Zwróćmy uwagę, że kolor biały (“środek” gradientu) to nie 50%, ale ok. 37% (Trzaskowski w przeciętnej gminie otrzymał właśnie tyle). Innymi słowy, na pomarańczowo są zaznaczone gminy, w których Trzaskowski uzyskał ponadprzeciętnie dużo, a niekoniecznie więcej od Nawrockiego. Gdyby kolorem białym zaznaczyć wynik 50% (remis), odcienie granatowego pojawiłyby się w 78% gminach, bo w tylu więcej głosów otrzymał Nawrocki.
Jest to ważna uwaga, choć niekoniecznie z punktu widzenia postulowanego podziału na Polskę wschodnią i zachodnią (lub “zabory”). Bo wciąż można twierdzić, że istnieje tu pewna granica między gminami “sprzyjającymi” danemu kandydatowi (nawet jeśli w nich przegrał).
Uprośćmy teraz tę mapę, redukując liczbę kolorów do dwóch.

Jak wcześniej, kolor pomarańczowy NIE oznacza, że w danej gminie wygrał Nawrocki, ale że otrzymał więcej głosów, niż w innych.
Demografia
Takie mapy sugerują, że to, po której stronie Polski żyjemy, ma bardzo duży wpływ na nasze preferencje wyborcze. I choć najpewniej mało kto uważa, że lokalizacja sama w sobie jest przyczyną tych różnic, wciąż jednak próbuje się wskazywać niekoniecznie sensowne wyjaśnienia, które nie uwzględniają dość podstawowych różnic między gminami. Poniżej pokazuję, jak różnią się one pod względem gęstości zaludnienia, płci, wieku i wykształcenia.






Korekta
Teraz skoryguję mapy wyborcze, tak by uwzględniały wyżej pokazane różnice demograficzne. W tym celu zastosuję pewną procedurę, która najpewniej nie będzie zrozumiała, jeśli Czytelnik nie zna się dobrze na statystyce. Dlatego zacznę od obrazowego opisu, potem przejdę do bardziej technicznego.
Widzimy wyraźnie, że w jednej gminie wyniki są inne, niż w drugiej, ale czy ta różnica byłaby tak samo duża, gdyby struktura wieku czy płci była podobna w tych gminach? Innymi słowy, jak wyglądałaby mapa poparcia, gdyby wszystkie gminy były porównywalne pod względem rozważanych cech? Na takie pytanie można odpowiedzieć przy pomocy modelu statystycznego, w którym wyniki wyborów próbuje się “wyjaśnić” przy pomocy pewnych przyjętych cech. Gdyby udało się to zrobić w 100%, znaczyłoby to, że odpowiedź na pytanie, dlaczego wyniki w gminach różnią się — w szczególności na wschodzie i zachodzie — byłaby bardzo prosta: bo mieszkańcy tych gmin różnią się tymi cechami (wykształceniem, wiekiem itd.)
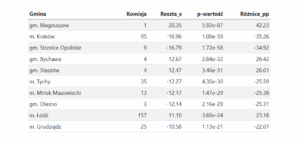
Z pewnością tak nie będzie, bo cechy te nie są wystarczające, by wyjaśnić różnice. Co jednak ważne, tę część zmienności wyników, której NIE da się wyjaśnić rozpatrywanymi cechami, da się uzyskać z modelu (są to tzw. reszty). Dzięki temu w dalszej analizie możemy abstrahować od tych cech i szukać innych przyczyn różnic między wschodem i zachodem, jeśli takowe wciąż będą widoczne. Wystarczy tylko analizować reszty, a nie surowe wyniki.
Pod względem technicznym, stosuję następującą procedurę. Po pierwsze, wykorzystuję bardziej szczegółowe informacje odnośnie do wieku i płci: procent kobiet w wieku 20-29, procent mężczyzn w wieku 20-29, procent kobiet w wieku 30-39 itd. Wykształcenie opisuję przy pomocy trzech zmiennych: procent osób z wykształceniem wyższym, średnim, zawodowym. Dopasowuję model, w którym wiążę procent głosów oddanych na Trzaskowskiego przy pomocy poniższych cech:
Trzaskowski ~ Wiek + Wykształcenie + Płeć + Zaludnienie + Urbanizacja.
Wynik Nawrockiego wynika wprost z wyniku Trzaskowskiego i dla modelu nie ma to znaczenia. Ponieważ zależności nie są liniowe, zastosowałem model GAM (uogólniony model addytywny). Następnie obliczam reszty z tego modelu, które można interpretować jako tę część wyników, która NIE wynika z uwzględnionych danych o strukturze ludności. Do reszt dodaję średni wynik wyborów dla gmin (jest to kosmetyczna zmiana, żeby skorygowane wyniki były w tej samej skali, co pierwotne dane).
Mapy skorygowane
Opisany wyżej model wyjaśnia aż 75% różnic w wynikach wyborów między gminami. Poniżej mapa powstała na bazie tego modelu (czyli po skorygowaniu o demografię) w porównaniu do oryginalnej.

Podział jest znacznie mniej widoczny, kolory bardziej “wyblakłe”, czyli gminy zbliżyły się do siebie pod względem wyników. Dodajmy od razu, że to zbliżenie jest konieczną konsekwencją tego, że udało nam się “wyjaśnić” dużą część zmienności wyników, tzn. ich rozrzut musi być teraz znacznie mniejszy (wyniki bliższe przeciętnym). Natomiast nie otrzymalibyśmy takiego efektu, gdyby wynik wyborów nie korelował z rozważanymi cechami — i dzięki takiej skorygowanej mapie możemy zobaczyć, jak silny jest ten związek.
Zauważmy też, że Warszawa stała się prawie biała. I na tym przykładzie wytłumaczę jeszcze, jak rozumieć tę skorygowaną mapę — bo oczywiście z tej analizy nie może wynikać, że w Warszawie był prawie remis, skoro było inaczej. Natomiast zdecydowanie wyższy wynik Trzaskowskiego da się wytłumaczyć, odwołując się do rozważanych tu cech gminy (wiek, płeć, wykształcenie, zaludnienie). I to na tyle dobrze, że po ich uwzględnieniu (“sprowadzeniu” ich do poziomu dla przeciętnej gminy w Polsce) wynik w Warszawie niczym się nie wyróżnia.
Można tu jednak mieć wątpliwości, czy jest to dobre podejście do postulowanego podziału na wschód i zachód. Jest on zwykle sprzedawany bez analizowania stopnia, w jakim gminy się różnią — wystarczy sam fakt, że istnieje jakaś granica. Dlatego podobnie jak poprzednio, użyję tylko dwóch kolorów, w zależności od tego, czy Trzaskowski uzyskał więcej głosów niż przeciętnie.

Podział jest mniej klarowny, mamy więcej pomarańczowych gmin na wschodzie i granatowych na zachodzie. Porównując do nieskorygowanej wersji, pomarańczowe gminy można traktować jako te, w których Trzaskowski uzyskał ponadprzeciętny wynik, nawet uwzględniając cechy demograficzne. A zmianę koloru z granatowego na pomarańczowy można interpretować następująco: wynik w tej gminie nie był dobry dla Trzaskowskiego, ale biorąc pod uwagę „niekorzystną” demografię, i tak powinien się cieszyć (trzeba tylko pamiętać, że zmiana koloru może występować nawet dla minimalnej różnicy, stąd lepszy jest gradient).
Religia
Po skorygowaniu wyników o rozważane cechy, można badać, które jeszcze są związane z preferencjami wyborczymi. Jedną z silniejszych jest procent osób deklarujących się jako katolicy: dodanie takiej cechy do modelu zwiększa stopień jego dopasowania z 75% do 84%. Im więcej takich osób w gminie, tym lepszy wynik Nawrockiego.
Warto tu dodać, że sama ta cecha (tzn. bez wieku, wykształcenia itd.) jest powiązana z wynikiem wyborów aż w 74%, czyli prawie tak samo, jak wszystkie rozważane wcześniej. Jednak wyciąganie z tego wniosku, że to przynależność do kościoła katolickiego najlepiej tłumaczy wyniki wyborów jest problematyczna, gdyż wiek, płeć czy wykształcenie można potraktować jako cechy bardziej “pierwotne”. Mogą one wpływać na religijność, ale w drugą stronę zależność powinna być mniejsza (choć zapewne też istnieje, może wpływać np. na dzietność, a przez to na strukturę wieku).
Krytyka
Na koniec przejdę do krytyki zastosowanego podejścia, wskazując jego słabsze strony.
-
Różnice procentowe w wynikach z perspektywy gminy są mylące, bo nie uwzględniają faktu, że gminy różnią się liczbą mieszkańców. Natomiast w żaden sposób tego nie normalizowałem, bo taki jest sens (lub bezsens) tego typu mapek, że procentowy wynik dla gminy jest traktowany jako pojedyncza obserwacja. Uwzględnia się jedynie powierzchnię gminy (tzn. widać ją na mapie).
-
Cała analiza jest wykonywana na cechach, które są podsumowaniem gmin, a nie cechami poszczególnych wyborców. Przenoszenie wniosków z takich agregatów na pojedyncze jednostki jest problematyczne i może prowadzić do tzw. błędu ekologicznego.
-
W modelu można uwzględnić znacznie więcej czynników, trzeba być tu jednak ostrożnym. Różnice między wschodem a zachodem są interpretowane jako wynikające z jakichś mentalnych różnic między zamieszkującymi te strony ludźmi — i mapki mają to ukazywać. Innymi słowy, mężczyzna w wieku 40 lat mieszkający w mieście na wschodzie ma różnić się od tego, który mieszka na zachodzie. I jeśli tak rzeczywiście jest, to wtedy takie mapy mają pewien sens. To, co próbuję tu pokazać, to że wyjaśnienie może być znacznie prostsze: np. na wschodzie jest mniej mężczyzn w wieku 40 lat mieszkających w mieście. Zauważmy jednak, że struktura wieku może częściowo wynikać z różnic w mentalności, gdyż mogą one wpływać np. na chęć posiadania dzieci, a w wyniku tego na piramidę wieku w danej gminie. Z drugiej strony, jest wiele czynników, które można potraktować jako niewynikające z mentalności, a których nie uwzględniam. I być może, biorąc je pod uwagę (czyli proponując lepszy model), różnice między wschodem a zachodem znikną zupełnie (niczego takiego jednak nie twierdzę).
-
Częściowo zostało to poruszone w poprzednim punkcie, ale chcę wyraźnie podkreślić, że z tej analizy nie wynika, że interpretacja różnic między gminami odwołująca się do zaborów nie ma sensu. Pomijając fakt, że nawet po skorygowaniu pewne różnice są widoczne, to np. struktura wykształcenia i wiek (poprzez dzietność) może być częściowo wynikiem właśnie zaborów.
-
Uwzględniam dane GUS o strukturze ludności w gminie, podczas gdy to, co nas interesuje, to struktura wśród osób, które zagłosowały. Jest ona na pewno inna (frekwencja zależy np. od wieku), natomiast można mieć nadzieję, że te odstępstwa są podobne na wschodzie i zachodzie — wtedy nie powinno mieć to dużego wpływu na wyniki.
Źródła
- Wyniki wyborów prezydenckich
- Struktura ludności, dane GUS (gęstość zaludnienia, ludność wg grup wieku i płci, dane o wykształceniu z Narodowego Spisu Powszechnego 2021)
- Przynależność wyznaniowa
- Jednostki administracyjne, mapa (plik “gminy”)