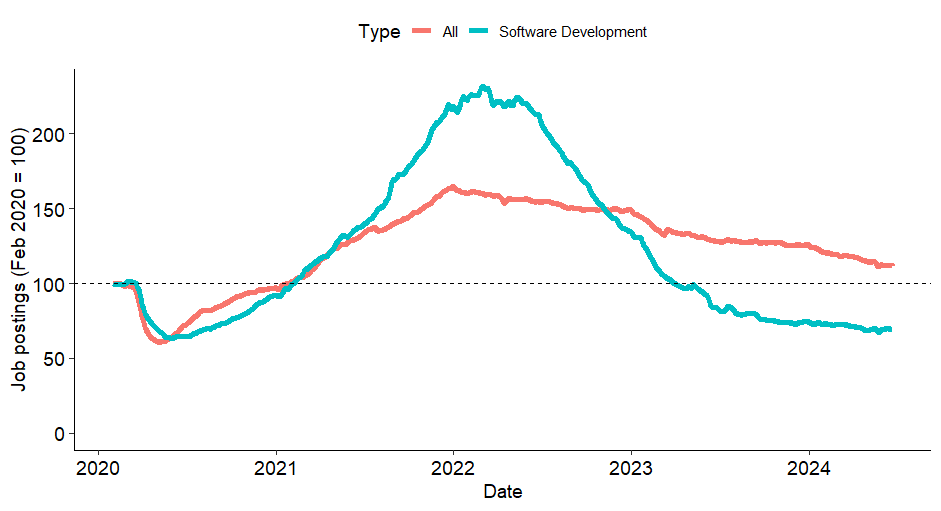
Spójrzmy na ten wykres, który swego czasu był dość popularny w internecie. Jest to liczba ofert pracy w USA w sekcji „software development” (specjalnie nie tłumaczę na polski, później się do tego odniosę). Na osi Y liczba ofert, ale tak przeskalowana, by w lutym 2020 wynosiła 100. Oryginalny wykres tutaj (może różnić się od tego poniżej, bo jest stale aktualizowany).
Praktycznie zawsze, gdy ktoś opublikuje taki wykres, pojawia się zarzut, że OŚ Y POWINNA ZACZYNAĆ SIĘ OD ZERA. I jest to nierzadko zarzut słuszny. Można powiedzieć, że rozpoczynanie osi Y od zera to rozsądna domyślna opcja.
Natomiast nie jest to zasada, przynajmniej w sensie ścisłym. Jeśli wykres zaczyna się od zera, to zero jest jakby jego częścią, dodatkowym punktem, który chcemy zaznaczyć. Ma on stanowić referencję, dzięki której wiarygodniej zinterpretujemy zaprezentowane różnice. Ale czasem zero jako referencja nie ma zupełnie sensu (np. gdy na osi Y jest temperatura w stopniach Celsjusza) albo niewielkie różnice są w praktyce dużymi różnicami i dobrze, żeby tak było przedstawione.
I tu dochodzimy do sedna uczciwości wykresów: różnice powinny być takie, jakie są w rzeczywistości. Ale nie da się ich zaprezentować OBIEKTYWNIE. Jak wiadomo, wszystko zależy od kontekstu – i to, jak jest przeskalowania oś (w tym gdzie się zaczyna) jest właśnie kontekstem. I ma być taki, by poprawnie zinterpretować zaprezentowane liczby.
Wróćmy do przedstawionego wykresu. Głównym problemem jest to, że może się wydawać, że w połowie 2020 i na początku 2024 liczba ofert spadł do zera. Czy jednak poza tym faktem, jest tu jakiś problem z percepcją? Czy gdyby oś Y zaczynała się od zera, to wzrost i spadek ofert pracy wydawałby się mniejszy?
Tak – ale tylko wtedy, jeśli stosunek osi (wysokość i szerokość wykresu) zostałyby zachowane. Poniżej ten sam wykres, ale w dwóch osłonach: w pierwszej zaczyna się od zera, w drugiej nie.
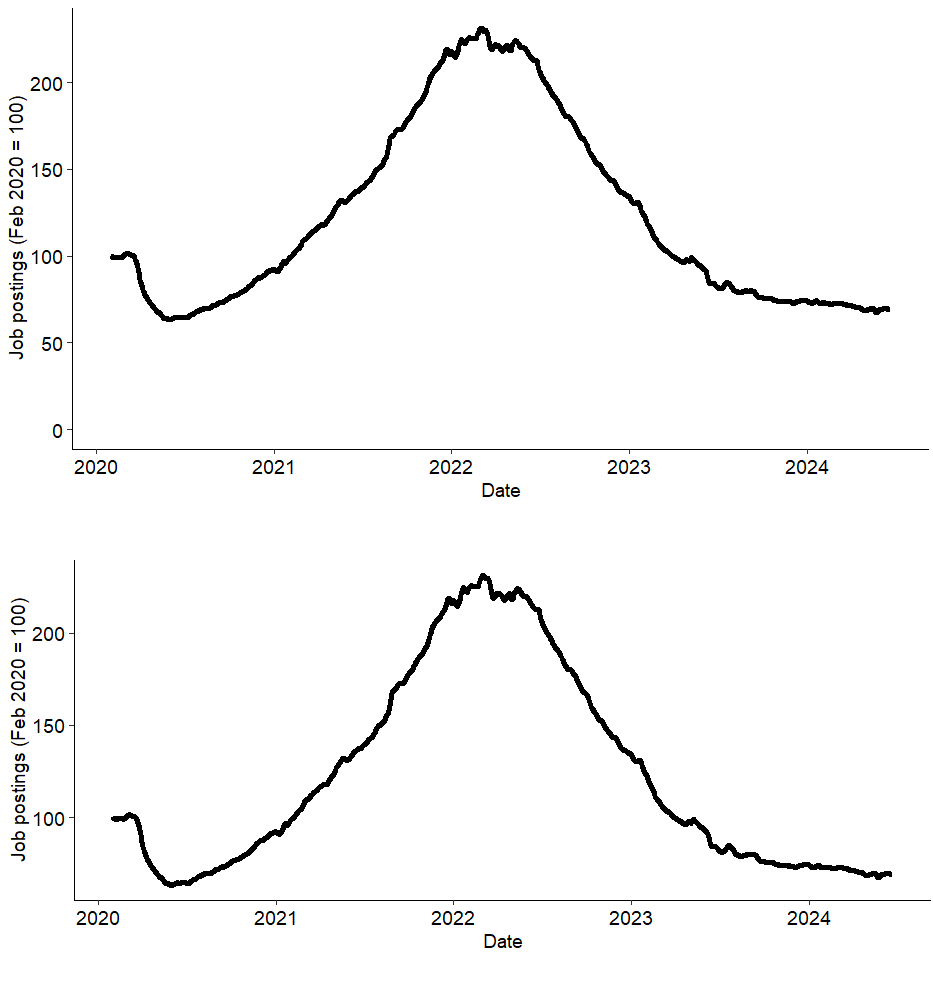
Czy widzicie jakąś różnicę? Moim zdaniem wrażenie jest dokładnie takie samo. Wynika to z tego, że wysokość pierwszego wykresu jest większa – i specjalnie tak ją dobrałem, by nachylenia krzywych były identyczne. Patrząc inaczej, pierwszy wykres różni się od drugiego jedynie białym prostokątem pod krzywą.
Dobrze, ale powiecie, że to manipulacja, bo pierwszy wykres ma inny stosunek długości!
A jaki jest właściwy?
Nie ma przecież żadnego „prawdziwego” czy domyślnego. To od nas zależy, czy wykres będzie w formie kwadratu, czy jedna z osi będzie dłuższa, a może znacznie dłuższa. Poniżej jeszcze raz te same dane, ale różnica w ofertach wydaje się znacznie większa, mimo że wykres zaczyna się od zera.
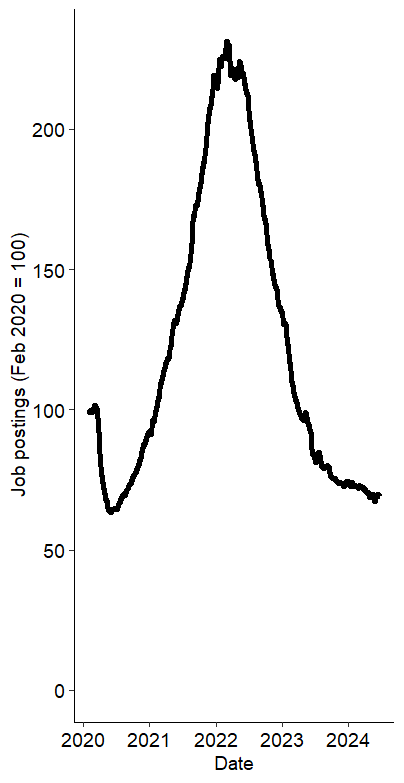
Jak się domyślacie, mogę tak zmienić stosunki osi, żeby krzywa wydała się prawie płaska.

Co jest ważniejsze?
Oczywiście poprawne (uczciwe) wykonanie wykresu jest ważne, mimo wszystko, patrząc całościowo na analizę danych, warto traktować to jako kwestię poboczną – szczególnie jeśli sami jesteśmy analitykami i zwracamy uwagę, jakie liczby pojawiają się na osi Y. A co jest tu znacznie ważniejsze?
a) Co to jest „software development”? Co wlicza się w tę kategorię? Wykres był komentowany jako spadek ofert pracy dla programistów – czy to jest dobre tłumaczenie „software development”?
b) To są nowe oferty pracy, czy te, które w danym dniu można było znaleźć? (skumulowane).
c) Skąd są te dane? Z różnych serwisów, czy może z jednego, który od pewnego momentu zaczął być mniej popularny?
d) Jak to wygląda na tle innych branż? Może ogólnie mamy spadek ogłoszeń?
Co do ostatniego punktu, to jest to prawda, co widać na poniższym wykresie. Wciąż dla „software development” spadek jest większy, ale już nie wygląda to tak spektakularnie.