Czy modele o  lub
lub  mogą być złe? Oczywiście: jeśli poprzednie były lepsze. Ale zostawmy ten przypadek na boku i zobaczmy, jak koszmarnie mogą w praktyce działać modele o podanych wyżej parametrach.
mogą być złe? Oczywiście: jeśli poprzednie były lepsze. Ale zostawmy ten przypadek na boku i zobaczmy, jak koszmarnie mogą w praktyce działać modele o podanych wyżej parametrach.
R kwadrat
Współczynnik  jest interpretowany jako procent wyjaśnianej wariancji przez model. Ala dla modeli nieliniowych zwykle definiuje się go jako kwadrat korelacji między rzeczywistymi wartościami Y, a szacowanymi przez model. Czyli
jest interpretowany jako procent wyjaśnianej wariancji przez model. Ala dla modeli nieliniowych zwykle definiuje się go jako kwadrat korelacji między rzeczywistymi wartościami Y, a szacowanymi przez model. Czyli
![\[R^2 = cor(Y, \hat{Y})^2.\]](https://danetyka.com/wp-content/ql-cache/quicklatex.com-5008675b02f678aa20b5dc6867045b86_l3.png "Rendered by QuickLaTeX.com")
Weźmy zatem prognozy zwracane przez dobry model A i załóżmy, że jakieś licho dodaje do nich pewną liczbę, przez co wszystkie prognozy są przeszacowane. Niestety, współczynnik tego nie zauważy.
Na poniższym obrazku, na osi poziomej mamy rzeczywiste wartości modelowanej cechy, na osi pionowej szacowane. W każdej sytuacji jest równe 99%. Czerwona linia to idealny model.
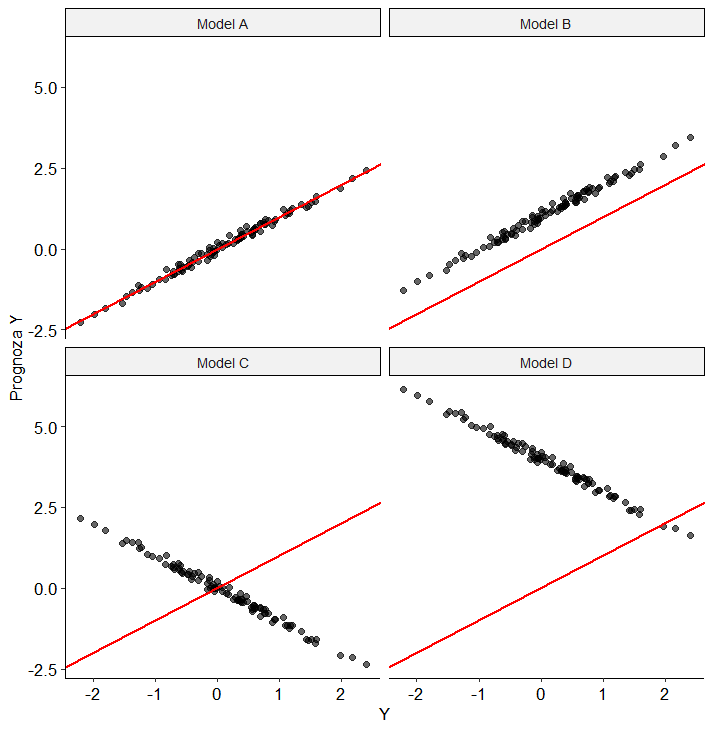
Jak widać, poleganie tylko na jest ryzykowne i możemy nie wykryć np. prostego dryfu modelu. W biznesie to  jest często lepszą miarą.
jest często lepszą miarą.
(Dla tych, co znają matematykę trochę lepiej, przedstawiony problem z wynika z faktu, że  ).
).
AUC
Weźmy teraz  . Powiedzmy, że model ma odróżniać koty od żbików i zwraca prawdopodobieństwo bycia żbikiem. Załóżmy, że ma taką własność, że jeśli wybiorę losową parę: żbik i kot, na 99% żbik otrzyma wyższe prawdopodobieństwo. W takim razie .
. Powiedzmy, że model ma odróżniać koty od żbików i zwraca prawdopodobieństwo bycia żbikiem. Załóżmy, że ma taką własność, że jeśli wybiorę losową parę: żbik i kot, na 99% żbik otrzyma wyższe prawdopodobieństwo. W takim razie .
Niech teraz to samo licho pomnoży te prawdopodobieństwa przez jakąś dodatnią liczbę i coś doda/odejmie. Porządek „prawdopodobieństw” się od tego nie zmieni, jedynie będą absurdalne (spoza przedziału ![[0, 1]](https://danetyka.com/wp-content/ql-cache/quicklatex.com-caffaae885a1287e3dfc31bfb1cd0694_l3.png "Rendered by QuickLaTeX.com") ). Problem w tym, że biznesowi zwykle zależy na odpowiednio skalibrowanych prawdopodobieństwach, a nie tylko na uporządkowaniu przypadków.
). Problem w tym, że biznesowi zwykle zależy na odpowiednio skalibrowanych prawdopodobieństwach, a nie tylko na uporządkowaniu przypadków.
Jeden z moich modeli na kaggle.com wyglądał tak:  , gdzie
, gdzie  był jednym z predyktorów, z wartościami SPOZA przedziału (szczegóły tutaj). Czyli jako prognozy („prawdopodobieństwa”) przesłałem po prostu wartości tego predyktora, bez żadnej transformacji. Metryką w tym turnieju było jednak i uzyskałem 0,857, co było jednym z lepszym wyników (
był jednym z predyktorów, z wartościami SPOZA przedziału (szczegóły tutaj). Czyli jako prognozy („prawdopodobieństwa”) przesłałem po prostu wartości tego predyktora, bez żadnej transformacji. Metryką w tym turnieju było jednak i uzyskałem 0,857, co było jednym z lepszym wyników ( zależało praktycznie tylko od , na dodatek monotonicznie).
zależało praktycznie tylko od , na dodatek monotonicznie).
Na koniec warto jednak dodać, że tak naprawdę wszystkie te modele na wykresach, jak również opisany przed chwilą, są w pewnym sensie dobre. Mają POTENCJAŁ — i wystarczy je tylko skalibrować. Istnieją odpowiednie techniki i można to zrobić na podstawie tych samych danych, na których zbudowaliśmy model.
Jeśli moje teksty są dla Ciebie wartościowe, na podany niżej adres email mogę przesłać Ci wiadomość, gdy pojawią się nowe. Zapraszam też na mój kanał na youtube.