Problem
Chcemy zbudować model, który klasyfikuje przypadki do jednej z grup, A lub B. Załóżmy, że zebraliśmy 60 tysięcy obserwacji. Budujemy pierwszy model, drugi, trzeci, ale żaden nie ma wystarczającej dokładności. Powodów może być wiele: stosowane do tej pory podejścia (algorytmy) były nieoptymalne, mamy za mało informacji (cech, kolumn) lub za mało obserwacji (wierszy).
Skupmy się na tym trzecim problemie. Pytanie brzmi, czy jeśli zbierzemy więcej danych (obserwacji, nie nowych cech), to czy będziemy w stanie zbudować lepszy model?
Wyjaśnijmy tylko, dlaczego dodanie kolejnych obserwacji może pomóc. Relacje, które próbujemy znaleźć, mogą być na tyle skomplikowane (subtelne), że możemy nie być w stanie ich wykryć. Być może mamy za mały budżet (dane), by to zrobić. Mogłoby się to udać, gdybyśmy np. dorzucili kolejną interakcję, kwadrat zmiennej czy dodatkową warstwę ukrytą w sieci neuronowej — ale nie stać nas na to.
Równie dobrze może to jednak nic nie dać. Co robić?
Sytuacja wydaje się beznadziejna, tzn. żeby się przekonać, czy kolejne obserwacje pomogą, trzeba chyba po prostu je zebrać? Jeśli chcemy być pewni, to owszem. Pokażę jednak sposób, dzięki któremu będzie można coś powiedzieć o tym, ile potencjalnie zyskamy, zbierając kolejne 10, 20, 30 tysięcy obserwacji.
Dodam, że przeczytałem o tym pomyśle w którymś z tekstów Andrew Ng, natomiast tutaj pokażę konkretnie, jak to przeprowadzić.
Dane
Weźmy dane o obiektach astronomicznych, można je pobrać stąd (swoją drogą, udało mi się zbudować najlepszy model na tych danych — jego krótki opis znajdziesz tutaj). Chcemy przewidzieć, czy dany obiekt to pulsar. W skrócie: pulsar go gwiazda, która bardzo szybko rotuje i wysyła mnóstwo promieniowania. Ale patrząc ogólniej, mamy po prostu problem klasyfikacyjny, w którym trzeba przewidzieć jedną z dwóch kategorii. Choć od razu dodam, że przedstawione podejście można zastosować również w problemie regresyjnym.
Dane wyglądają następująco:
| Mean | SD | Skewness | EK | Mean_curve | SD_curve | Skewness_curve | EK_curve | Class |
|---|---|---|---|---|---|---|---|---|
| 113.33 | 44.39 | 0.08 | 0.34 | 2.37 | 16.94 | 9.82 | 113.91 | 0 |
| 116.49 | 51.88 | 0.06 | -0.37 | 29.98 | 67.68 | 1.81 | 1.86 | 0 |
| 92.38 | 40.22 | 0.49 | 1.28 | 15.70 | 49.48 | 2.80 | 6.98 | 0 |
| 7.80 | 33.44 | 5.85 | 35.34 | 106.10 | 74.80 | 0.24 | -0.64 | 1 |
| 103.30 | 43.88 | 0.54 | 0.84 | 2.78 | 15.06 | 8.39 | 95.95 | 0 |
| 86.53 | 39.75 | 0.72 | 1.74 | 2.33 | 18.46 | 9.18 | 88.48 | 0 |
| 99.24 | 44.57 | 0.26 | 0.42 | 4.84 | 27.86 | 6.27 | 40.23 | 0 |
| 79.83 | 37.74 | 1.37 | 4.75 | 22.14 | 54.16 | 2.66 | 7.06 | 1 |
W całym zbiorze jest prawie 120 tysięcy obserwacji, ale wybieram z niego tylko 60 tysięcy i zakładam, że to są całe dostępne dane (pozostałe będą mi potrzebne później). Mamy 8 ilościowych predyktorów, Class jest zmienną celu. Nie będę wyjaśniał, co oznaczają poszczególne zmienne, bo jest to dość skomplikowanie, a nie ma tutaj większego znaczenia. Co najwyżej warto wiedzieć, że są one bardzo silne i nie ma tu potrzeby tworzenia nowych (feature engineering) na ich podstawie. To, czy gwiazda jest pulsarem, zależy praktycznie tylko od tych cech — a w takim razie oczekujemy bardzo dobrego modelu (o wysokiej dokładności).
Procedura
Zastosuję las losowy, bo jest wystarczająco elastyczny i nie wymaga tuningu hiperparametrów (oczywiście ogólnie warto to zrobić, natomiast można przyjąć sensowne wartości domyślne). Chodzi mi tu głównie o oszczędność czasu, bo jak zaraz zobaczymy, model będzie dopasowywany wielokrotnie.
Pomysł polega na tym, by zbudować model na podzbiorach danych o różnych wielkościach i sprawdzić, na ile są dobre. Będę losował podzbiory o wielkości n w przedziale od 10 tysięcy do 60 tysięcy (czyli całe dane). Żeby dostać dokładniejsze oszacowania, jak model działa, zrobię to po 10 razy dla każdej wielkości n. Oprócz tego użyję 10-krotnej walidacji krzyżowej, także w sumie dla każdego podzbioru dostanę 100 wyników. Jako miarę dokładności wybrałem logloss.
Tutaj zauważmy, że dla 60 tysięcy obserwacji jest problem, bo nie da się wybrać podzbioru. Wciąż jednak można użyć powtarzanej walidacji krzyżowej i tak właśnie robię (swoją drogą, testowałem też bootstrap).
Wyniki
Poniżej wykres zależności między logloss a liczbą obserwacji, na podstawie której został zbudowany model (słupki to błędy standardowe).

Ostatni punkt to logloss równe 0,0425.
Dwie uwagi. Liczbę obserwacji pomnożyłem przez współczynnik 0,9. Skoro używam 10-krotnej walidacji krzyżowej, to w rzeczywistości buduję model nie na np. 10 tysiącach obserwacji, ale 9 tysiącach. Po drugie, im więcej obserwacji, tym błędy standardowe są mniej wiarygodne z racji coraz większej korelacji (dla 60 tysięcy mamy powtarzaną walidację krzyżową, dla mniejszych zbiorów “prawie” powtarzaną). W każdym przypadku liczę te błędy jako odchylenie standardowe dzielone przez 10 (pierwiastek z liczby wyników), co nie jest poprawne dla dużych podzbiorów. Choć szczerze mówiąc, ciężko mi powiedzieć, w jakim stopniu jest to błędne.
Co możemy zrobić z tymi wynikami? Dopasować do nich model (“meta-model”) i na jego podstawie przewidzieć wartości logloss dla większych n — żeby ocenić, czy opłaca się zbierać więcej danych.
Czy tak wolno?
Pytanie, czy to ma sens. Oczywiście chcemy tu dokonać ekstrapolacji i nie możemy być niczego pewni. Nie mniej jednak relacja, którą przed chwilą narysowaliśmy, nie wygląda przypadkowo. Oczywiście nie wystarczy, że jest malejąca, bo to jasne — ale wygląda na to, że jest tu jakieś konkretne tempo poprawy. A skoro tak, można mieć nadzieję, że się utrzyma (choć oczywiście nie wiadomo, jak długo).
Meta-model
Tutaj powinno się dłużej zastanowić nad odpowiednią postacią modelu. Ja zastosowałem ważoną regresję liniową: logloss ~ 1/n + 1/n^2 (sam człon 1/n był niewystarczający). Nie myślałem jednak nad tym zbyt intensywnie, po prostu chciałem, by model był dobrze dopasowany do danych oraz żeby był nierosnący.
Ważę odwrotnością błędu standardowego. I tutaj wychodzi problem, że te dalsze są zaniżone. Z drugiej strony, nawet jeśli dla każdego n błąd standardowy byłby tak samo duży, to i tak wolałbym się bardziej dopasować do większych n (podobnie jak w szeregach czasowych zwykle ważniejsze są najbardziej aktualne dane). Stąd być może w praktyce to nie jest duży problem.
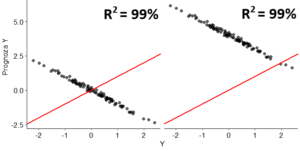
Jak mamy model, możemy dokonać prognoz. Poniżej na czerwono wartości wynikające z modelu, na niebiesko prognozy.

Warto tu zauważyć, że logloss według modelu nie dąży do zera wraz ze wzrostem liczby obserwacji (co oczywiście ma sens, bo przecież na Y na pewno wpływają czynniki, których nie mamy), ale do wyrazu wolnego! W przypadku tego modelu wyraz wolny wynosi 0,0407, także zakładając, że zaproponowane podejście oraz model są w porządku, to nawet jeśli zebralibyśmy nieskończenie wiele obserwacji, nie jesteśmy w stanie zejść niżej, niż do poziomu 0,0407.
Żeby było jasne: wcale nie polecam tak zakładać. Tzn. należy do tych wyników podchodzić z dużą ostrożnością (wrócę do tego na końcu). I pamiętać, że używamy konkretnego modelu (lasu losowego), a przy większej liczbie obserwacji być może lepsza okazałaby się sieć neuronowa.
Weryfikacja
Sprawdźmy zatem, jakie rzeczywiście logloss otrzymamy, zbierając dodatkowe kilkadziesiąt tysięcy obserwacji. Wykorzystam teraz te pozostałe dane, które na początku pominąłem. Uwaga: to nie są dane testowe! Tzn. łączę je z tymi, na których pracowałem do tej pory, i dopasowuję model na całości.
Tu znów jest problem z walidacją krzyżową, która jednorazowo bierze pod uwagę tylko 90% obserwacji. Całe dane to 117 tysięcy wierszy, więc w rzeczywistości testujemy działanie modelu na ok. 106 tysiącach obserwacji. Podstawiam tę wartość do mojego meta-modelu i otrzymuję odpowiedź, że logloss powinno wynosić 0,0419.
A jak jest naprawdę? Sprawdzam przy pomocy powtarzanej 10 razy 10-krotnej walidacji krzyżowej i otrzymuję… uwaga, chwila prawdy… 0,0419. Wygląda to nadzwyczaj dobrze, ale poniżej ostrzegam przed nadmiernym optymizmem.
Komentarz
Mimo że brzmi to obiecująco, byłbym ostrożny z uogólnianiem. Po pierwsze, poruszamy się na granicy błędu standardowego. Gdybym zmienił ziarno generatora losowego, najpewniej nie wyglądałoby to tak dobrze (choć od razu mówię, że nie manipulowałem nim). Po drugie, bardzo dużo zależy od zaproponowanego meta-modelu.
Możliwe, że w praktyce, zamiast dokładnych obliczeń, rozsądniej jest jedynie spojrzeć na wykres i ocenić, czy wciąż widać wyraźny spadek, czy jednak dość mocno się wypłaszcza i nie ma co spodziewać się dużej poprawy, gdy zbierzemy kolejne obserwacje.
Cały kod dostępny tutaj.
Jeśli moje teksty są dla Ciebie wartościowe, na podany niżej adres email mogę przesłać Ci wiadomość, gdy pojawią się nowe. Zapraszam też na mój kanał na youtube.